
- Today
- Total
작심삼일
Unpaired Image Super-Resolution using Pseudo-Supervision (CVPR 20) 본문
Unpaired Image Super-Resolution using Pseudo-Supervision (CVPR 20)
yun_s 2021. 8. 20. 10:02My Summary & Opinion
어느 순간부터 SR를 풀기 위한 네트워크들은, 네트워크의 구조를 바꾸기보다 획기적인 loss function을 사용해왔다. (MSE loss가 SR과 맞지 않는다는 것은 이미 널리 알려진 지 오래다.)
그러면서 점점 loss를 하나만 사용하는 것이 아닌, 여러 다양한 loss들을 합친 것이 더 뛰어난 성능을 보였고, 이 논문도 그중 하나다.
이 논문이 만든 새로운 loss는 cycle consistency loss와 geometric ensemble loss가 있다.
Cycle consistency loss는 CycleGAN의 one-to-one mapping으로 인한 한계를 뛰어넘기위해 만들어졌고, geometric ensemble loss는 flip과 rotation 된 input을 사용할 수 있도록 고안됐다.
Real-world SR에서 뛰어난 성능을 보였다는 것이 인상깊었다.
사실 이 논문을 하기 전에 CycleGAN부터 정리를 해야 했다는 생각이 들었다.
다음 논문은 CycleGAN으로 해야지
Introduction
최근 여러 논문들은 blind SR이나 GAN처럼 HR-LR 이미지를 쌍으로 사용하지 않고 SR을 하는 방법을 연구하고 있다.
Blind SR은 arbitrary kernel로 만들어진 LR로부터 HR을 복원하는 것이다.
이런 논문들은 이 'blindness'를 bluring과 같은 한정된 방법으로만 사용했는데, 실제 LR은 이런 방법으로 생성되지 않는다.
이와 달리, GAN-based unpaired SR은 degradation 없이 LR과 HR을 mapping 하는 것을 학습한다.
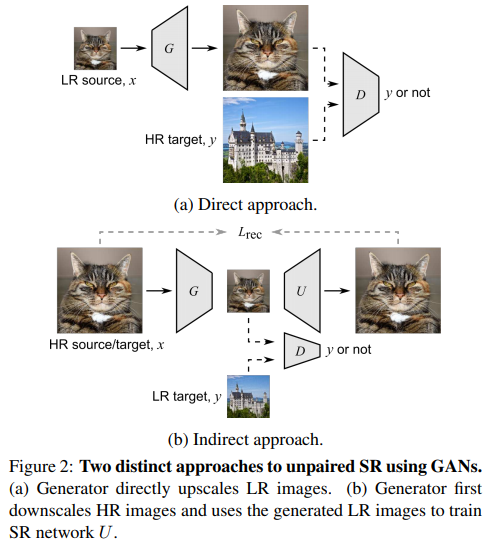
Direct approach
Generator는 LR을 upscale 해서 HR discriminator를 속인다.
이 방법의 단점은, generator를 학습시킬 때 pixel-wise loss function을 사용할 수 없다는 것이다.
Paired SR 방법에서는 pixel-wise loss가 중요한 역할을 했다.
Indirect approach
Generator가 HR을 downsampling 해서 LR discriminator를 속였다.
이 방법의 단점은 실제 test 할 때의 성능이 학습할 때만큼 나오지 않는다는 것이다.
Our approach
위 두 가지 방법의 단점을 모두 극복하는 방법이다.
Related Work
Paired Image Super-Resolution
대부분 SR 연구들은 HR을 줄여서 만든 paired training dataset을 사용한다.
Blind Image Super-Resolution
ZSSR, IKC 등이 있다. (이 부분은 내가 잘 살펴보지 않아서 현재는 잘 모른다. 앞으로 이쪽 분야도 봐야겠다.)
Unpaired Image Super-Resolution
CycleGan, DualGAN 등이 있다.
Proposed Method
우리의 목표는 unpaired training samples $x, y$를 이용해서 LR source domain과 HR target domain을 잇는 mapping $F_{XY}$를 학습하는 것이다.
$y_{\downarrow} (\in Y_{\downarrow})$: downscaled HR (with Gaussian blur & bicubic)
$G_{XY}$: mapping from $X$ to $Y_{\downarrow}$
$U_{XY}$: upscaling mapping from $Y_{\downarrow}$ to $Y$
Loss functions
1. Adversarial loss
두 generator, $G_{XY_{\downarrow}}, G_{Y_{\downarrow}X}$에 대해서 모두 adverserial loss를 사용했다.
본 논문에서는 두 generator들이 HR discriminator $D_{X_{\uparrow}}$를 이용해 optimize 한다.
2. Cycle consistency loss
CycleGAN은 cycle($X \rightarrow Y \rightarrow X$ and $Y \rightarrow X \rightarrow Y$)을 이용해야 하기 때문에 one-to-one mapping으로 학습된다.
우리는 이 한계를 극복하기 위해 cycle consistency를 한쪽에서만 사용하기로 했다.
$L_{cyc}(G_{Y_{\downarrow}X}, G_{XY_{\downarrow}}) = ||G_{XY_{\downarrow}}\circ G_{Y_{downarrow}X}(y_{\downarrow})-y_{\downarrow}||_1$
이렇게 cycle consistency를 한쪽에서만 사용하면, $G_{Y_{\downarrow}X}$는 one-to-many가 가능해진다.
3. Identity mapping loss
Identity mapping loss는 painting $\rightarrow$ photo를 할 때 색을 유지하기 위해 CycleGAN에서 처음 소개됐다.
같은 이유로 본 논문에서도 이 loss를 사용했다.
4. Geometric ensemble loss
Geometric consistency는 scene geometry를 유지하기 위해 사용됐다.
이에 영감 받아, input image를 flip 하고 rotation해도 그 결과를 바꾸지 않는 geometric ensemble loss를 고안했다.
$L_{geo}(G_{XY_{\downarrow}}) = ||G_{XY_{\downarrow}}(x) - \displaystyle \sum ^8 _{i=1}T_i^{-1} (G_{XY_{\downarrow}}(T_i(x)))/8||_1$
$\{T_i\}^8_{i=1}$: eight disticnt patterns of flip and rotation
Network Architecture
1. $G_{XY_{\downarrow}}$ and $U_{Y_{\downarrow}Y}$
$G_{XY_{\downarrow}}$와 $U_{Y_{\downarrow}Y}$는 RCAN-based로 만들었다.
RCAN은 residual groups(RGs) 10개로 만들어졌는데, 각 RG는 residual channel attention block(RCAB) 20개로 이루어져 있다.
우리가 사용한 $G_{XY_{\downarrow}}$와 $U_{Y_{\downarrow}Y}$는 10 RCAB로 이루어진 RG 5개를 사용했다.
2. $G_{Y_{\downarrow}X}$
$G_{Y_{\downarrow}X}$는 $5 \times 5$ 필터의 residual block과 $1 \times 1$ 필터의 fusion layers로 구성했다.
각 conv layer 뒤에는 BN과 LeakyReLU를 붙였다.
3.$D_X$, $D_{Y_{\downarrow}}$ and $D_{X_{\uparrow}}$
LR discriminator인 $D_X$와 $D_{Y_{\downarrow}}$는 stride를 1로 한 conv layer 5개로 구성했다.
제일 마지막 층 빼고 각 conv layer 뒤에는 LeakyReLU만 사용했다.
HR discriminator인 $D_{X_{\uparrow}}$도 같은 구조를 사용했지만, 처음 층의 stride만 2로 했다.

Experiments
Realistic distortion, synthetic distortion 등 다양한 분야에서 SOTA다.


Conclusion
Unpaired setting에서도 가능한 SR 네트워크를 제안한다.
제안하는 네트워크는 pseudo-clean LR 이미지를 생성해서 학습에 사용한다.
Real-world SR에서도 뛰어난 성능을 보인다.
Reference
Maeda, Shunta. "Unpaired image super-resolution using pseudo-supervision." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.



