
- Today
- Total
작심삼일
[C3D 리뷰] Learning Spatiotemporal Features with 3D Convolutional Networks (ICCV 15) 본문
[C3D 리뷰] Learning Spatiotemporal Features with 3D Convolutional Networks (ICCV 15)
yun_s 2022. 8. 16. 20:55My Summary & Opinion
3D conv를 효과적으로 잘 사용할 수 있는 구조를 실험적으로 알아냈다.
또한 많은 실험을 통해 3D conv가 어떻게 성능을 높이는 지 분석했다.
여러 가지를 실험을 통해 분석을 잘한 논문이라고 생각된다.
Introduction
비디오를 다루는 모델은 여러 비디오에 잘 동작하기 위해 generic해야하며, 많은 비디오를 다루기 위해 compact해야하고, 많은 비디오를 빨리 다루기 위해 efficient해야하며, 사용하기 편하게 simple해야한다.
그동안은 image based deep featur를 사용했지만, motion modeling이 부족했기 때문에 video에는 적절하지 않았다.
그래서 우리는 spatio-temporal feature를 학습시킬 수 있는 deep 3D ConvNet을 소개한다.
이 3D convolution은 3×3×3일 때 최적의 성능을 낸다.
Related Work
그전에 사용되던 SIFT, HOG, Harris coner detector등을 사용한 tracker들은 연산이 많이 필요하고, 그렇기 때문에 큰 dataset에는 적용하기 힘들었다.
Spatio-temporal 정보를 사용하는 stacked ISA또한 연산량이 많았다.
우리가 제안하는 모델과 제일 비슷한 3D ConvNet을 사용하는 모델도 있었는데, 이 모델은 사람이 먼저 detect한 후, head tracking을 진행했다.
이와 달리, 우리는 비디오 프레임 전체를 input으로 넣고, 어떤 preprocessing도 필요하지 않다.
Learning Features with 3D ConvNets
3D convolution and pooling
3D ConvNet은 2D ConvNet과 달리 3D convolution과 3D pooling을 이용하기 때문에 temporal information을 더 잘 사용한다.
그래서 우리는 3D ConvNet의 최적화된 architecture를 정의하려한다.
c×l×h×w라 할 때, c는 channel, l은 프레임 수, h,w는 각각 높이 너비라 하자.
웅리는 비디오를 non-overlapped 16-frame으로 잘라서 네트워크 입력으로 넣었다.
Input dimension은 3×16×128×171이다.
그리고 학습동안 3×16×112×112로 random cropping을 해서 사용했다.
네트워크는 conv layer 5개, pooling layer 5개, fc layer 2개, softmax loss layer를 사용했다.

네트워크 구조에 따라 어떤 구조가 더 성능이 좋은지 확인하기 위해 일정하게 kernel temporal depth를 모두 1, 3, 5, 7로 통일한 모델과, 3-3-5-5-7로 증가시킨 모델, 7-5-5-3-3으로 감소시킨 모델들을 비교했다.
그 결과 아래 그래프를 보면 알 수 있다싶이, 3으로 통일 시킨 모델이 제일 좋았다.
Spatiotemporal feature learning
아래 그림처럼 모델을 만들어서 학습을 진행시켰다.
그 결과는 아래 그림처럼 분석된다.
처음 몇 프레임에서 물체를 잡고, 그 뒤로 움직임을 파악한다.
Action recognition
Table 3에 따르면 결과가 좋다는 것을 알 수 있고, Figure 5, 6을 보면 같은 dimention일 때 더 compact하게 학습한다는 것을 알 수 있다.
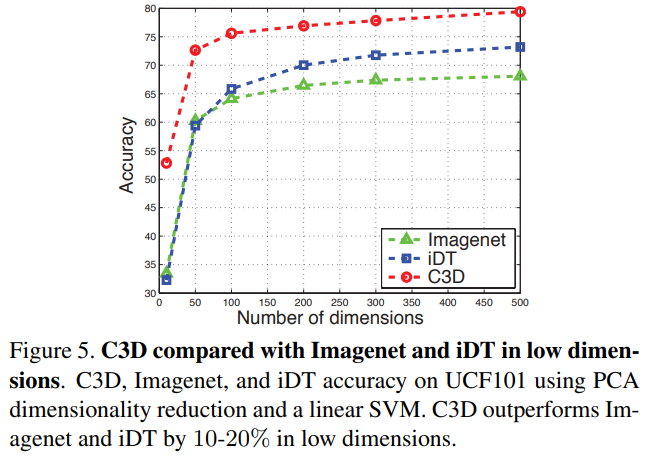

그밖에도 Action similarity labeling, Scene and Object recongition에서도 좋은 성능을 보였다.
Reference
Tran, Du, et al. "Learning spatiotemporal features with 3d convolutional networks." Proceedings of the IEEE international conference on computer vision. 2015.



