
- Today
- Total
작심삼일
[EnhanceNet 리뷰] Single Image Super-ResolutionThrough Automated Texture Synthesis (ICCV 17) 본문
[EnhanceNet 리뷰] Single Image Super-ResolutionThrough Automated Texture Synthesis (ICCV 17)
yun_s 2021. 5. 10. 13:00My Summary & Opinion
PSNR에 의구심을 갖고 진행되는 연구가 많고, EnhanceNet도 그중 하나다.
기존의 Euclidean loss를 사용해 학습한 네트워크로는 PSNR 기준으로 SOTA를 찍었고, photo-realistic한 이미지를 만들기 위해 adversarial training, perceptual loss, texture transfer loss를 이용했다.
Adversarial training과 perceptual loss는 이전의 SRGAN에서 사용했으니 texture transfer loss가 이 논문의 핵심이 되겠다.
Texture transfer loss가 style transfer에서 사용되는 loss라는데, 그 영역에 대한 공부는 하지 않았지만, 수식을 보니 perceptual loss와 비슷한 콘셉트이지만 local 하게 진행되는 듯하다.
SRGAN때 부터 어떤 층을 어떻게 쌓을까보다 내가 원하는 방향으로 가기 위해 loss를 어떻게 설계할까 위주로 발전하고 있다.
Image generation에서 가져온 adversarial training이라던가 style transfer에서 가져온 texture transfer loss를 보면, SISR분야만 공부하기보다 여러 영역을 파악해두면 새로운 컨셉이나 아이디어를 떠올리기 좋을 것이다.
Introduction
SISR 문제를 풀 때 일어나는 심각한 문제는 downsampling factor를 크게 잡았을 때 overly smoothing 되어 생기는 high-frequency 정보의 손실이다.
이 문제는 많은 알고리즘들이 MSE를 최소화하는 방식을 사용하기 때문에 일어난다.
이런 방식은 사람이 이미지의 질(quality)을 방식과 매우 다르다.
아래 그림을 보면 PSNR로 계산했을 때 SOTA인 왼쪽 그림보다, 비록 PSNR은 더 낮지만 오른쪽 그림이 더 sharp 하다.
MSE는 계산하기 편하지만, 그 결과는 자연스럽지 않고, 타당해 보이지 않는다.

이 논문에서는 adversarial training과 perceptual loss를 사용해 SISR의 직관적인 질을 높이는 방법을 제안한다.
Related work
SISR의 모델들은 MSE를 최소화하는 방식으로 학습되기 때문에 그 결과가 선명하지 못하고 high-frequency texture가 부족하다.
이를 해결하기 위해 CNN에 perceptual loss를 사용하는 방식이 제안되었고, 더 선명한 결과를 냈다.
Adversarial network는 이미지 생성(image generation) 영역에서 선명한 결과를 내고 있었지만, 이는 대부분 얼굴 생성에만 사용되고 있다.
SRGAN은 우리와 비슷한 방식을 개발했지만, 그들은 feed-forward CNN을 adversarial network와 결합하며 perceptual loss를 사용했다.
우리와 달리 SRGAN은 local matching을 하지 않았다.
Single image super-resolution
$I_{LR} = d_{\alpha}(I_{HR})$, $d_{\alpha}$: downsampling operator
$f(I_{LR}) = I_{est} \approx I_{HR}$, $f \approx d^{-1}$
Deep learning 방식들은 요즘 multi-layerd neural network를 사용해 Euclidean loss $||I_{est} - I_{HR}||$를 최소화하도록 학습되고 있다.
모델들이 PSNR로 측정했을 때 최고의 성능을 내도록 학습이 되면, 그 결과는 선명하지 못하고 high-frequency 성분이 부족하다.
이것은 SISR의 모호성 때문이다: downsapming 과정에서 high-frequency 성분이 사라지면 pixel-wise 정확도로 그 detail을 살리는 방법은 없다.
그렇기 때문에 SOTA 모델도 해당 영역의 모든 texture의 mean을 생산하게 되는 것이다.

위 그림을 통해 이 현상을 간단히 설명하겠다.
$(I)$. $I_{HR}$에는 $1 \times 2$ 크기의 수직, 수평 선이 무작위로 존재한다.
$(II)$. $I_{LR}$에서는 이런 수직, 수평 선들을 구분할 수 없기 때문에 single pixel로 표현된다.
$(III)$. Euclidean loss로 학습된 모델은 모든 가능한 정답의 mean을 생산한다. 왜냐하면 이것이 가장 낮은 MSE이기 때문이다.
$(IV)$. Adversarial loss는 sharp 한 결과를 가지고 있지만, 정확히 $I_{HR}$과 일치하지는 않는다. 왜냐하면 모델이 각 선의 원본을 알 수 없기 때문이다.
흥미롭게도, 이 결과는 MSE 결과보다 더 낮은 PSNR를 갖는다.
Method
Architecture

모델의 구조는 위의 표와 같다.
LR input은 output 이미지보다 작기 때문에 언젠가 upsampling 되어야 한다.
LR을 bicubic upsampling 한 뒤에 네트워크에 넣는 방법은 간단하지만 계산량이 매우 늘어난다.
그래서 어떤 논문에서는 convolutional transpose layer를 사용해 feature map을 upsampling 하도록 했다.
Convolutional transpose layer는 checkerboard artifact를 생성한다고 알려져 있다.
이를 해결하기 위해 다른 논문에서는 nearest-neighbor upsampling을 사용하지만, 우리가 제안하는 네트워크 구조에서는 이런 방식도 checkerboard artifact를 생성한다.
이런 artifact들을 없애기 위해 upsamping 후에 conv layer를 한 번 더 적용한다.
Training and loss functions
1. Pixel-wise loss in the image-space
우리 모델을 MSE로 학습시킨 것을 baseline으로 했다.
$L_E = ||I_{est} - I_{HR}||$
2. Perceptual loss in feature space
Image space에서 distance를 계산하는 대신, $I_{est}$와 $I_{HR}$를 differentiable function $\phi$로 feature space로 보낸 후 distance를 계산한다.
$L_P = ||\phi(I_{est}) - \phi(I_{HR})||^2_2$
이렇게 하면 pixel-accuracy가 높진 않지만 비슷한 feature representation을 갖는 이미지를 생산할 수 있다.
$\phi$는 pre-trained implementation of VGG-19를 사용한다.
3. Texture matching loss (style transfer에서 사용됨)
정답 이미지가 있을 때, output 이미지는 pre-trained network에서 추출된 statistic을 matching 하는 방식으로 생성된다.
$L_T = ||G(\phi(I_{est})) - G(\phi(I_{HR}))||^2_2$
Gram matrix $G(F) = F F^T$
이 방법은 반복적인 작업이기 때문에 느리고, target texture가 있을 때만 사용할 수 있다.
우리는 SISR에 style transfer loss를 사용하기로 했다.
네트워크가 high-resolution texture에 가까워지도록 학습하는 대신, $I_{est}$와 $I_{HR}$ 사이의 local 한 영역에서 비슷한 texture를 갖도록 texture loss $L_T$를 계산했다.
그로 인해 네트워크는 HR image들과 같은 local texture를 가지도록 학습된다.
4. Adversarial training
Adversarial training은 진짜처럼 보이는 이미지를 생산할 때 유용한 방법으로 증명됐다.
원래는 generative network $G$가 랜덤 한 벡터들 $z$로부터 이미지 $x$의 data space와 mapping 하도록 학습된다.
이와 동시에 discriminative network $D$는 generated samples $G(z)$로부터 진짜 이미지 $x$를 구분하도록 학습된다.
$G$는 다음을 최소화하도록 한다.
$L_A = -\log(D(G()z))$
$D$는 다음을 최소화하도록 한다.
$L_D = -\log(D(x)) - \log(1-D(G(z)))$
SISR에서는 $G$는 $x$ 대신 $I_{LR}$를 input으로 하고, output은 $I_{est}$가 되도록 예상한다.
Evaluation
Effect of different losses

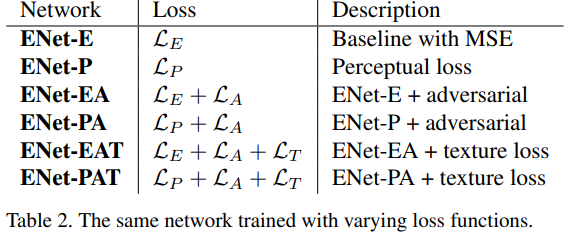
Perceptual loss를 사용한 ENet-P는 ENet-E보다 더 선명한 결과를 내지만, texture 부분에서 detail이 사라진다.
ENet-PA는 high-frequency detail을 더하며 더 선명해진다.
하지만 가끔 smooth 영역에서 원치 않은 high-frequency noise를 더한다.
Texture loss까지 사용한 ENet-PAT은 local 하게 의미 있는 texture를 만들어 artifact들을 없앤다.
ENet-PAT가 제일 그럴듯한 이미지를 만들었지만, ENet-E가 PSNR이 제일 높다.

Comparison with other approaches

Discussion, limitations and future work
Euclidean loss, adversarial training, perceptual loss, text transfer loss를 사용하며 SOTA를 달성하는 네트워크를 제안한다.
ENet-PAT는 그럴듯하지만, pixel-wise 하게 GT와 일치하지 않는다.
게다가 adversarial training은 가끔 원치 않는 artifact를 생성한다.
Reference
Sajjadi, Mehdi SM, Bernhard Scholkopf, and Michael Hirsch. "Enhancenet: Single image super-resolution through automated texture synthesis." Proceedings of the IEEE International Conference on Computer Vision. 2017.



