

- Today
- Total
작심삼일
[Memnet 리뷰] MemNet: A Persistent Memory Network for Image Restoration (ICCV 17) 본문
[Memnet 리뷰] MemNet: A Persistent Memory Network for Image Restoration (ICCV 17)
yun_s 2021. 5. 4. 10:30My Summary & Opinion
CNN의 층을 더 깊게 쌓을수록, SR에 대한 성능이 좋아지는 추세였다.
하지만 너무 깊어지면 long-term dependency 때문에 더 이상 성능이 높아지지 않는 경향이 있는데, 이를 memory block으로 해결했다.
Memory block 안의 gate unit으로 long-term 하게, recursive unit으로 short-term 하게 학습이 되도록 했다.
개인적으로는 memory block이라는 컨셉을 사용한 것은 좋지만, 이 논문의 마지막에 언급한 DenseNet이 간단하면서 획기적인 구조를 가진다고 생각한다.
MemNet은 뭔가 이것저것 좋은 것들을 다 합친 느낌이랄까...
물론 이런 것들을 잘 합치는 것도 좋지만, 간단하면서 획기적인 구조를 만드는 것이 더 좋아 보인다.
Introduction
VDSR 같은 전통적인 CNN은 아래 Fig. 1의 (a)처럼 single-path feed-forward 한 구조를 가지고 있다.
이 구조에서는 state는 그 직전 state에만 영향을 받아 short-term memory라고 할 수 있다.
그에 대한 변형으로 REDNet이나 ResNet 같은 구조는 skip connection을 가지고 있다.
이 구조는 short-term memory와 다르게 특정한 prior state로부터 영향받기 때문에, restricted long-term memory라 할 수 있다.
하지만 앞서 말한 모델들 모두 모델이 깊어질수록 long-term memory가 부족한 문제가 있다.

이 문제를 해결하기 위해 very deep persistent memory network(MemNet)을 제안한다.
MemNet은 먼저 Feature Extraction Net(FENet)이 저해상도 이미지에서 feature를 추출한다.
그 후, densely connected structure인 memory block이 이미지를 복원한다.
마지막으로 Reconstruction Net(ReconNet)이 residual을 학습한다.
MemNet에서 중요한 점은, memory block이 recursive unit과 gate unit을 가지고 있다는 점이다.
Recursive unit에서 short-term memory를 생성하고, 이전 memory block들에서 long-term memory를 가진다. (Fig. 1의 (c)에서 초록 화살표)
이 논문의 concept를 요약하자면 다음과 같다.
* Long-term dependency를 위해 memory block으로 gating mechanism을 만들었다.
각 memory block마다 gate unit이 long-term memory를 얼마나 사용할 것인지, short-term memory를 얼마나 저장할 것인지 학습한다.
* 80 conv layers로 매우 깊은 end-to-end 구조를 가지고 있다.
* 한 구조로 세 가지 영역, Image denoising, SR, JPEG deblocking에서 SOTA다.
Related Work
SR문제를 풀기 위해 깊은 CNN이 많이 사용되고 있다.
Skip connection이나 auto-encoder 구조도 사용되고 있다.
MemNet for Image Restoration

1. Basic Network Architecture
MemNet은 세 가지 구조(feature extraction FENet, memory blocks, reconstruction net ReconNet)로 이루어져 있다.
$x$와 $y$를 각각 MemNet의 입력과 출력이라고 하자.
FENet은 noisy 하거나 blurry 한 이미지에서 feature를 추출하기 위해 conv layers가 사용된다.
$B_0 = f_{ext}(x)$
$f_{ext}$: feature extraction function, $B_0$: extracted feature
Memory block는 feature mapping의 역할을 한다.
$B_m = \mathcal{M}_m (B_{m-1}) = \mathcal{M}_m(\mathcal{M}_{m-1}(...(\mathcal{M}_1(B_0))...))$
$\mathcal{M}_m$: $m$-th memory block function
마지막으로, 저해상도 이미지에서 고해상도 이미지로 바로 mapping 하는 대신에 residual image를 복원하기 위해 ReconNet의 conv layer를 사용했다.
최종적으로 MemNet은 다음과 같이 쓸 수 있다.
$y = \mathcal{D}(x) = f_{rec}(\mathcal{M}_m(\mathcal{M}_{m-1}(...(\mathcal{M}_1(B_0))...))) + x$
2. Memory Block
Memory block은 recursive unit과 gate unit으로 이루어져 있다.
Recursive unit은 뇌의 recursive 시냅스처럼 행동하는 non-linear function으로 사용된다.
Object recognition에서 뛰어난 성능을 보인 residual building block을 사용한다.
m번째 memory block의 residual building block은 다음과 같이 구성된다.
$H^r_m = \mathcal{R}_m(H^{r-1}_m) = \mathcal{F}(H^{r-1}_m, W_m) + H^{r-1}_m$
$H^{r-1}_m$ & $H^r_m$: input & output of the $r$-th residual building block, $\mathcal{R}$: residual building block
Gate Unit은 지속적인 학습을 위해 사용된다.
$B_m = f^{gate}_m(B^{gate}_m) = W^{gate}_m \tau(B^{gate}_m)$
$f^{gate}_m$: $1 \times 1$ conv, $B_m$: output of the $m$-th memory block
Long-term memory의 weight가 이전 state를 얼마나 사용할지를 결정하고, short-term memory의 weight는 현재 state를 얼마나 저장할지를 결정한다.
3. Multi-Supervised MemNet

Memory block의 모든 output은 하나의 reconstruction net $\hat{f}_{rec}$로 들어가 다음을 생성한다.
$y_m = \hat{f}_{rec}(x, B_m) = x + f_{rec}(B_m)$
$\{y_m\}^M_{m=1}$ : intermediate predictions
이 prediction들은 weighted averaging으로 최종 output $y$를 생성한다.
4. Dense Connections for Image Restoration
여기서는 MemNet의 long-term dense connection이 어떻게 이미지 복원에 도움이 되는지 설명한다.
매우 깊은 네트워크에서는 전형적인 feedforward 한 CNN의 특성 때문에 끝단으로 갈수록 mid/high-frequency 정보가 사라질 수 있다.
Dense connection을 사용하면 이런 문제를 해결할 수 있다.
Discussions
Difference to Highway Network
MemNet과 Highway network 둘 다 gate unit을 사용한 깊은 CNN 모델이다.Highway network와 달리 MemNet은 short-term과 long-term 메모리를 합쳐 사용한다.또한, Highway network가 픽셀 단위로 weighted sum을 하는 반면, MemNet은 feature map단위로 weighted sum을 하기 때문에 다음과 같은 두 가지 장점이 있다.첫째, 파라미터 수가 줄고, 둘째, overfitting 될 가능성이 줄어든다.
Difference to DRCN
DRCN의 기본 구조는 conv layer지만, MemNet은 memory block을 기본 구조로 가진다.
DRCN은 conv layer에 대한 weight가 share 되지만, MemNet에서는 memory block의 weight들은 모두 다르게 정해진다.
DRCN에서는 기본 구조들(conv layers) 사이에 dense connection이 없다.
Difference to DenseNet
DenseNet은 object recognition을 위해 설계되었다.
DenseNet은 local 하게 densely connection이 존재하지만, MemNet은 global 하게 존재한다.
Experiments
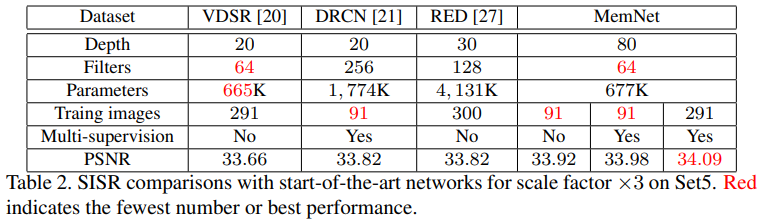

네트워크가 깊어질수록 성능이 더 좋아진다.
JPEG deblocking에서도 성능이 좋다.
Memory block을 많이 사용할수록 weight norm의 variance는 작아진다.
Conclusions
Very deep end-to-end MemNet은 image restoration을 위해 설계됐다.
Memory block이 gating mechanism의 역할을 해서 이전 CNN 구조들과 달리 long-term dependency 문제를 해결한다.
Memory block 안의 recursive unit으로 short-term memory도 이용한다.
SOTA다.
Reference
Tai, Ying, et al. "Memnet: A persistent memory network for image restoration." Proceedings of the IEEE international conference on computer vision. 2017.



