
- Today
- Total
작심삼일
[CycleGAN 리뷰] Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks (ICCV 17) 본문
[CycleGAN 리뷰] Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks (ICCV 17)
yun_s 2021. 9. 14. 12:17My Summary & Opinion
Style transfer 영역을 처음 접하게 된 것이 이 CycleGAN이다.
원리는 간단하다.
NLP에서 번역을 학습시킬 때 사용하는 것처럼 cycle 하게 학습시키는 것이다.
그 결과는 아래처럼 좋게 나온 것이 많았다.
하지만 예상하지 못한 결과가 나온 것도 많았는데, 이는 uncontrollable한 GAN의 특성도 반영된 것이고, Unpaired 한 데이터를 사용하기 때문에 우리의 생각과 다르게 학습 데이터의 특성을 뽑는 경우도 있었다.
데이터를 매우 다양하게 넣으면 해결될 문제지만, 항상 예외는 존재하기에 이를 해결한 논문을 읽어보고 싶다.
Introduction
본 논문에서는, 한 이미지 모음에서의 특성을 뽑아 다른 이미지 모음에 적용시키는 방법을 소개한다.
이 문제는 image-to-image translation이라고 볼 수 있다.
Computer vision, Image processing 영역에서의 연구는 대부분 아래 그림(Fig. 2)의 왼쪽처럼 image pair를 사용해 supervised setting에서 이루어졌다.
하지만 paired training data를 만드는 것은 어렵고 비용이 많이 든다.
그래서 우리는 unpaired data를 사용한 알고리즘을 개발하고자 했고, cycle consistent하게 학습을 시켰다.

Related work
Generative Adversarial Networks (GANs)
GAN의 핵심 아이디어는 generated image들이 real photos와 구분할 수 없게 만드는 adversarial loss에 있다.
우리는 translated image들이 target domain에 있는 image들과 구분되지 않게 하기위해 adversarial loss를 사용했다.
Image-to-Image Translation
이전의 image-to-image translation은 paired dataset을 사용했지만, 우리는 unpaired dataset을 사용하고자 한다.
Unpaired Image-to-Image Translation
이전까지의 unpaired image-to-image translation은 predefined metric space에서의 input과 output이 비슷하게 만들기 위해 adversarial network를 사용했지만, 우리는 그런 방식을 사용하지 않았다.
Cycle Consistency
Structured data를 regularize하기 위해 transitivity를 사용하는 방법은 오래전부터 사용되었다.
이 논문에서는, 우리는 G와 F를 비슷하게 만드는 similar loss를 소개할 것이다.
Neural Style Transfer
우리가 제안하는 방법은 painting → photo 등 다양한 분야로 확장시킬 수 있을 것이다.
Formulation
우리의 목표는 두 도메인 X,Y를 잇는 mapping function을 학습시키는 것이다.
아래 그림(Fig. 3)의 (a)처럼 제안하는 모델은 mapping을 두 개 가지고 있다: G:X→Y와 F:Y→X.
게다가 adversarial discriminator 두 개를 가지고 있다.
DX는 image{x}와 translated images{F(y)}를 구분하기 위한 것이고, DY는 {y}와 {G(x)}를 구분하기 위한 것이다.
Adversarial Loss
우리는 mapping function 두 개에 모두 adversarial loss를 적용했다.
LGAN(G,DY,X,Y)=Ey pdata(y)[logDY(y)]+Ex pdata(x)[log(1−DY(G(x)))]
Cycle Consistency Loss
Adversarial training은 이론적으로 mapping을 학습한다.
하지만 네트워크는 한 이미지를 target domian에 있는 여러 이미지랑 mapping할 수 있다.
Adversarial loss 하나로는 individual input xi가 우리가 원하는 output yi와 mapping 한다는 보장이 없다.
그렇기 때문에 mapping function이 cycle-consistent하게 했다.
위 그림(Fig. 3)의 (b)를 보면 x→G(x)→F(G(x))≈x인 것을 볼 수 있는데, 이를 forward cycle consistency로 부르기로 했다.
이와 비슷하게 Fig. 3의 (c)에서는 backward cycle consistency를 볼 수 있다.
우리는 cycle consistency loss를 사용해 위와 같은 consistency를 만들도록 했다.
Lcyc(G,F)=Ex pdata(x)[||F(G(X))−x||1]+Ey pdata(y)[||G(F(y))−y||1]
위 loss에 있는 L1 norm을 F(G(x))와 x, G(F(y))와 y 사이의 adversarial loss로 바꿔보려 했지만, 성능 향상이 없었다.
Full Objective
최종 loss는 다음과 같다.
L(G,F,DX,DY)=LGAN(G,DY,X,Y)+LGAN(F,DX,Y,X)+λLcyc(G,F)
여기서 λ는 두 objective 사이의 relative importance를 조절한다.
우리 모델이 autoencoder와 비슷하게 보일 수 있다.
하지만 autoencoder는 다른 내부 구조를 가지고 있다.
Autoencoder는 translation of the image를 다른 domain으로 나타내는 intermediate representation을 통해 스스로 mapping한다.
Implementation
network: 3 conv layers + several residual blocks + 2 fractionally-strided convolutions with stride 12 + 1 conv layer
λ=10
learning rate: 0.0002
Results

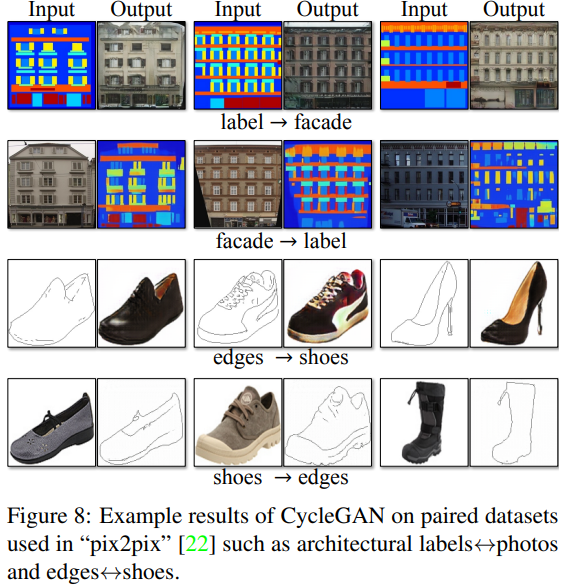
Limitations and Discussion
제안하는 방법이 그럴듯한 결과를 냈지만, 항상 좋은 결과만 낸 것은 아니다.
아래 그림(Fig. 17)을 보면 나쁜 결과들이 있다.
몇몇 실패들은 training dataset에서의 특성에 있다.
예를 들면, 말을 얼룩말로 바꾸는 경우에는 사람이 말을 타고 있는 이미지가 학습 데이터에 없었다.

Reference
Zhu, Jun-Yan, et al. "Unpaired image-to-image translation using cycle-consistent adversarial networks." Proceedings of the IEEE international conference on computer vision. 2017.
'Deep Learning > Vision' 카테고리의 다른 글
| [FFC 리뷰] Fast Fourier Convolution (NIPS 20) (0) | 2022.08.08 |
|---|---|
| [YOLOv4 리뷰] Optimal Speed and Accuracy of Object Detection (arXiv 20) (0) | 2022.08.07 |
| [YOLOv3 리뷰] YOLOv3: An Incremental Improvement (arXiv 18) (0) | 2022.08.04 |
| [YOLOv2 리뷰] YOLO9000: Better, Faster, Stronger (CVPR 17) (0) | 2022.08.02 |
| [YOLO v1 리뷰] You Only Look Once: Unified, Real-Time Object Detection (CVPR 16) (0) | 2022.07.29 |



