
- Today
- Total
작심삼일
[YOLO v1 리뷰] You Only Look Once: Unified, Real-Time Object Detection (CVPR 16) 본문
[YOLO v1 리뷰] You Only Look Once: Unified, Real-Time Object Detection (CVPR 16)
yun_s 2022. 7. 29. 11:15My Summary & Opinion
YOLO는 bounding box와 classification을 동시에 진행함으로써 그 속도를 매우 빠르게 했다.
또한 이미지 전체를 보고 판단하기 때문에 Fast R-CNN보다 background error가 적다.
왜냐하면 Fast R-CNN는 각 패치별로 classification을 진행하기 때문이다.
YOLO의 단점은 명확하다.
박스별로 하나의 class만 예측하기 때문에 겹쳐 있는 물체는 잘 판단하지 못하고,
Data에 없던 새로운 형태의 bounding box는 잘 예측하지 못한다.
그렇게 유명한 YOLO 논문을 이제서야 읽었는데, 왜이렇게 사람들이 열광했는지 알 것 같았다.
Bounding box와 classification을 동시에 진행하는 아이디어가 기발하다.
Introduction
현재까지 classifier에 사용된 방법은 DPM처럼 sliding window를 사용하거나, R-CNN처럼 bounding box를 친 후 classification을 진행하는 방식이었다.
하지만 이런 방식은 너무 느리고, 각각 따로 학습(bounding box & classification)을 시켜야하기 때문에 optimize하기 어렵다.
그래서 우리는 object detection을 single regression problem으로 취급해서, image pixel로부터 bounding vox coordinate와 class probability를 바로 뽑도록 했다.
YOLO는 전체 이미지를 학습해서 바로 detection을 진행한다.
Contribution은 크게 세가지다.
1) YOLO는 매우 빠르다.
2) YOLO는 이미지에서 global하게 찾는다.
3) YOLO는 어떤 물체의 generalizable representation을 학습한다.
단점 또한 존재한다.
1) YOLO는 SOTA보다 정확도가 낮다.
2) box별로 classification을 진행하기 때문에 작은 물체나 겹쳐있는 물체는 잘 판단하지 못한다.
Unified Detection
제안하는 네트워크는 bounding box를 예측하기 위해 이미지 전체를 사용한다.

다음과 같은 방법으로 진행된다.
1) 입력 이미지를 S×S grid로 자른다.
2) 어떤 물체의 중심이 grid안에 있게되면, 그 grid cell로부터 물체를 감지한다.
3) 각 grid cell은 B개의 bounding box를 predict하고, 각 box별로 confidence score를 계산한다.
4) 각 grid cell별로 Pr(Classi|Object) class probabilities를 계산한다.
Network Design
GoogLeNet 구조를 본따서 만들었다.
다만 GoogLeNet의 inception module 대신 1×1 reduction layers와 3×3 convolutional layers를 붙여서 사용했다.
YOLO는 24층이고, Fast YOLO 9층이다.
최종 output size는 7×7×30이다.
Training
보통 이미지가 있으면 그 물체가 있는 곳보다 배경이 있는 곳이 더 많다.
배경만 있는 곳의 grid cell은 object가 없기 때문에 confidence score는 0이 되고, object를 포함하고 있는 grid한테까지 영향을 미친다.
이를 해결하기 위해 bounding box coordinate prediction의 loss를 늘리고, object를 가지고 있지 않은 box의 confidence prediction loss를 줄였다.
YOLO는 gird cell별로 bounding box를 여러개 예측한다.
이중에서 가장 높은 IOU를 가진 box를 선택하도록 했다.
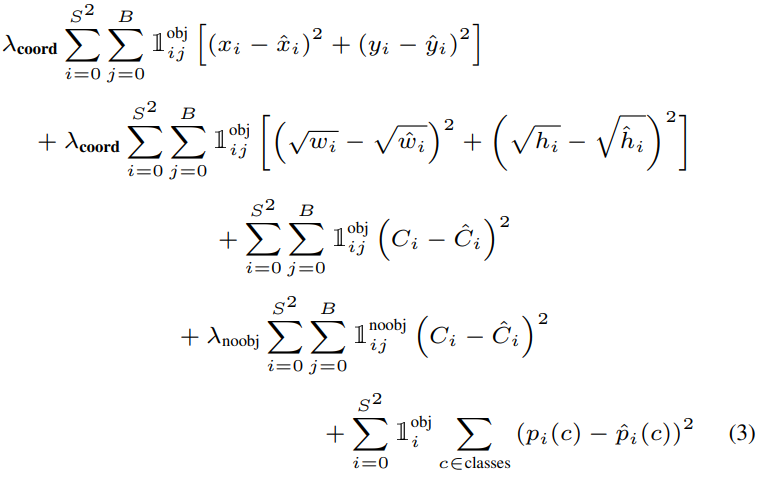
grid cell 안에 물체가 있을 때만 classification error를 계산한다는 것에 주의하자.
또한, overfitting을 방지하기 위해 dropout과 data augmentation을 진행했다.
Limitations of YOLO
YOLO에서 bounding box prediction을 하기 때문에 각 grid cell별로 bounding box를 두개만 가지고 (B=2), class는 단 하나만 가질수 있다.
그래서 여러 물체들이 뭉쳐있는 경우는 판단할 수 없다.
(예를 들면, 강아지 고양이가 한 grid안에 있는 경우 class는 하나로 출력해야하기 때문에 에러가 날 수 밖에 없다.)
또한 data에 없는 다른 크기와 모양의 bounding box는 잘 예측하지 못한다.
Experiments

Background Error(배경만 있는 곳인데 물체가 있다고 잘못 탐지하는 것)가 많이 줄었다.
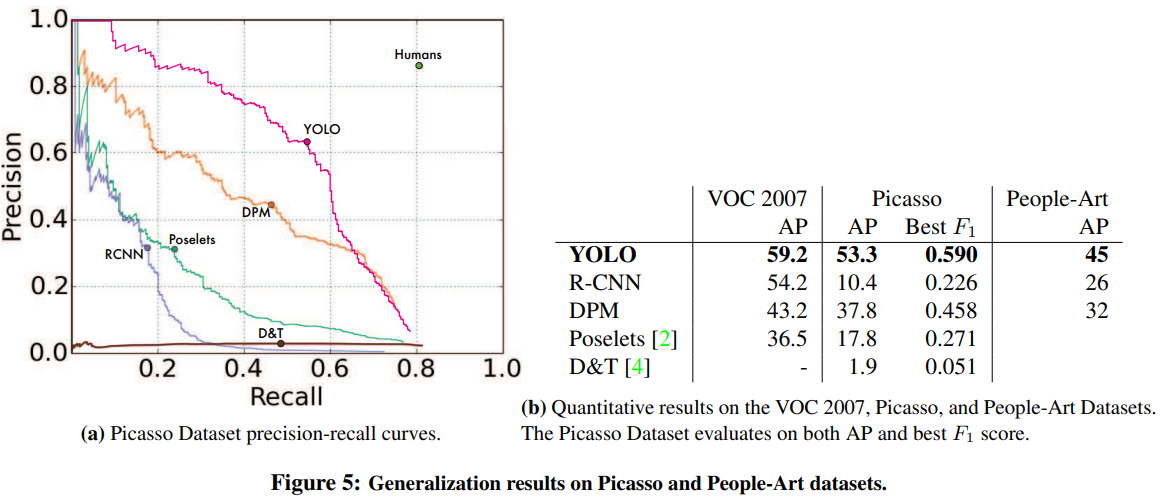

성능 좋다.
Reference
Redmon, Joseph, et al. "You only look once: Unified, real-time object detection." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.



