
- Today
- Total
작심삼일
[Hifi-GAN 리뷰] HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis (NIPS 20) 본문
[Hifi-GAN 리뷰] HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis (NIPS 20)
yun_s 2021. 10. 14. 17:25My Opinion
발화 음성이 다양한 주기의 신호로 이루어져 있기 때문에 discriminator를 여러 개의 sub-discriminator로 구성했다.
Generator는 MRF, discriminator는 MPD와 MSD로 이루어져 있다.또한, 성능을 높이기위해 3종류의 loss를 사용했다.
(GAN loss, Mel-spectrogram loss, Feature Matching loss)이 loss들은 자주 사용되는 loss인데도 불구하고 21년이 된 지금까지, 20년에 만들어진 이 HiFI-GAN보다 성능이 좋은 모델이 없다는 것이 대단하다.
그 이유는 아마 discriminator를 sub-discriminators로 만든 것에 있지 않을까 싶다.
Introduction
최근 neural network의 발전에 따라 음성 합성 기술은 급격한 발전을 겪었다.
대부분의 음성 합성 네트워크는 두 단계로 이루어진다: 1) Mel-spectrogram 생성, 2) waveform 생성
이 논문에서는, mel-spectrogram에서 waveform을 생성하는, 2번째 단계의 모델에 초점을 맞췄다.
이전에는 autoregressive(AR)이나 flow-based 모델들이 사용됐다.
제안하는 HiFi-GAN은 앞서 언급한 두 가지 종류의 모델들보다 속도도 빠르고 그 성능도 더 뛰어나다.
발화 음성은 다양한 주기의 sinusoidal 신호로 이루어져 있기 때문에 realistic 한 발화 음성을 만들기 위해서는 periodic pattern을 생성하는 것이 중요하다.
그래서 우리는 raw waveform에서 각각 특정한 periodic 부분을 맡는 sub-discriminator로 구성된 discriminator를 제안한다.
이 구조는 우리 모델이 realistic한 발화를 만드는 데 매우 중요하다.
HiFi-GAN
1. Overview
HiFi-GAN은 generator 한 개와 discriminator 두 개로 이루어져 있다.
Generator와 discriminators는 additional loss 두 개를 이용해서 adversarial 하게 학습된다.
2. Generator
Generator는 fully convolutional neural network이다.
Mel-spectrogram을 입력으로 받은 후 transposed convolution을 통해 raw waveform의 temporal resolution까지 upsampling을 진행한다.
모든 transposed convolution 뒤에는 multi-receptive field fusion(MRF) 모듈이 붙는다.
Multi-Receptive Field Fusion
MRF는 병렬적으로 다양한 길이의 패턴을 관찰한다.
특히, MRF 모듈은 multiple residual block의 출력의 합을 출력으로 한다.
다양한 receptive filed pattern을 형성하기 위해 각 residual block의 kernel size나 dilation rate를 다양하게 한다.

3. Discriminator
Realistic한 발화 음성을 만들기 위해서 long-term dependency를 아는 것은 중요하다.
이 문제는 generator와 discriminator의 receptive fields를 증가하는 방식으로 해결했다.
또 다른 문제는, 발화 음성은 다양한 주기를 가진 sinusoidal 신호들로 구성되기 때문에 음성 데이터의 기저에 있는 다양한 주기의 패턴을 아는 것이다.
우리는 음성의 periodic signal을 나눠 각각 다루기 위해 여러 개의 sub-discriminator로 이루어진 multi-period discriminator(MPD)를 제안한다.
그리고, 연속되는 패턴과 long-term dependency를 잡기 위해 MelGAN에서 사용된 multi-scale discriminator(MSD)도 사용했다.
Multi-Period Discriminator
MPD는 $p$ 주기로 일정하게 나뉜 입력 음성을 다루는 sub-discriminators로 이루어져 있다.
Sub-discriminator들은 각각 입력 음성의 다른 부분을 맡아 다른 implicit structure를 찾기 위해 설계됐다.
아래 그림(Fig. 2b)을 보면 알 수 있다시피, 먼저 $T$ 길이의 1D raw audio를 높이 $T/p$와 너비 $p$의 2D 데이터로 바꾼다.
Periodic samples를 독립적으로 처리하기 위해 MPD의 모든 conv layer의 kernel size는 1로 했다.
입력 데이터를 2D로 바꿈으로써, MPD에서 나온 gradient는 입력 음성의 모든 time step에 전달될 수 있다.

Multi-Scale Discriminator
MPD의 각 sub-discriminator는 분해된 sample만 사용하기 때문에 연속된 음성을 평가하기 위해 MSD를 추가했다.
MSD의 구조는 MelGAN에서 가져왔는데, 다른 input scale($\times 1, \times 1/2, \times 1/4$)에서 동작하는 sub-discriminator 3개로 이루어진다.
Training Loss Terms
GAN Loss
Generator와 discriminator는 LS-GAN처럼 non-vanishing gradient flow를 하기 위해 기본적인 GAN의 binary cross-entropy 부분을 Least square loss function로 바꿔서 학습했다.
Discriminator는 GT sample을 1, generator로 만들어진 sample을 0으로 구분하도록 학습됐다.
Generator는 sample quality를 높여서 discriminator를 속이도록 학습됐다.
Generator $G$와 discriminator $D$의 loss는 다음과 같이 정의된다.
$L_{Adv}(D;G) = \mathbb{E}_{(x, s)} \left[ (D(x)-1)^2 + (D(G(s)))^2\right]$
$L_{Adv}(G;D) = \mathbb{E} \left[ (D(G(s)) - 1)^2\right]$
$x$: GT audio, $s$: mel-spectrogram of GT audio
Mel-Spectrogram Loss
Generator의 training efficiency를 높이고 생성된 음성의 품질을 높이기 위해 mel-spectrogram loss를 추가했다.
이전 연구들에 따르면 time-frequency distribution은 multi-resolution spectrogram과 adversarial loss function에 효과적이다.
Mel-spectrogram loss는 generator가 만들어낸 waveform의 mel-spectrogram과 GT waveform의 L1 distance다.
$L_{Mel}(G) = \mathbb{E}_{(x, s)} \left[ ||\phi(x) - \phi(G(s))||_1 \right]$
$\phi$: function that transforms a waveform into the corresponding mel-spectrogram
Feature Matching Loss
Feature matching loss는 GT sample과 generated sample 사이의 feature of the discriminator의 차이로 측정하는 학습된 similarity metric이다.
Generator에 사용했다.
Feature matching loss는 GT sample과 각 feature space에서 생성된 sample 간의 L1 distance다.
Feature matching loss는 다음과 같이 정의된다.
$L_{FM}(G;D) = \mathbb{E}_{(x,s)} \left[ \displaystyle \sum^T_{i=1} ||D^i(x) - D^i(G(s))||_1\right]$
$T$: number of layers in the discriminator, $D^i, N_i$: features and the number of features in the $i4-th layer of the discriminator
Final Loss
$L_G = L_{Adv}(G;D) + \lambda _{fm}L_{FM}(G;D) + \lambda_{mel}L_{Mel}(G)$
$L_D = L_{Adv}(D;G)$
$\lambda_{fm}$=2, $\lambda_{mel}$=45
Experiments
LJSpeech dataset을 이용해서 학습시켰다.
Unseen speaker에 대해서 평가하기 위해 VCTK multi-speaker dataset을 사용했다.
Results
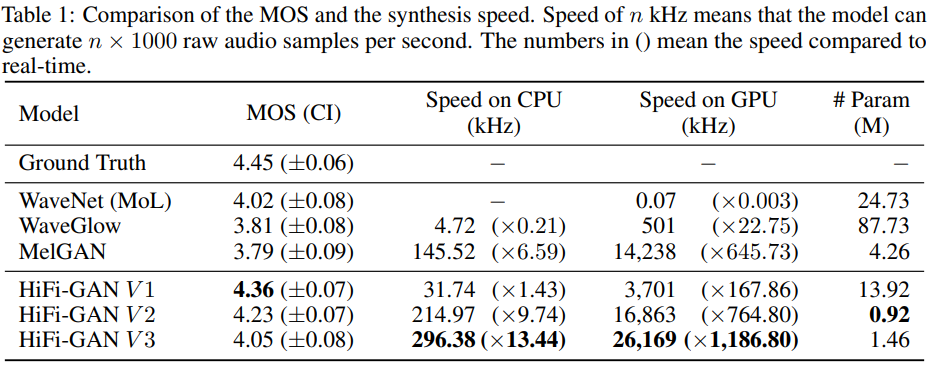

Conclusion
본 논문에서는 좋은 품질의 발화 음성을 만들 수 있는 HiFi-GAN을 제안한다.
제안하는 모델은 human level에 견줄 수 있을 정도로 성능이 뛰어날 뿐 아니라 속도도 빠르다.
Unseen speaker에 대해서도 잘한다.
Reference
Kong, Jungil, Jaehyeon Kim, and Jaekyoung Bae. "HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis." Advances in Neural Information Processing Systems 33 (2020).


