
- Today
- Total
작심삼일
[MelGAN 리뷰] Generative Adversarial Networks forConditional Waveform Synthesis (NIPS 19) 본문
[MelGAN 리뷰] Generative Adversarial Networks forConditional Waveform Synthesis (NIPS 19)
yun_s 2021. 10. 18. 17:42My Opinion
TTS 쪽 논문 중 하나인 HiFi-GAN을 읽다가, HiFi-GAN의 구조 중 하나가 MelGAN을 따라 했다는 부분을 보고 MelGAN을 읽게 되었다.
MelGAN 이전의 논문을 읽지않아서 이 논문의 novelty가 뭔지는 잘 모르겠지만, mel-spectrogram에서 audio를 만드는 이 분야에서 GAN을 처음으로 적용했다 하니, 그것이 이 논문의 novelty가 아닐까 싶다.
Discriminator에서 multi-scale 구조를 사용했는데, 이것이 vision 쪽의 Laplacian Pyramid와 비슷한 개념인 것 같다.
그렇다면 왜 3단계만 사용했는지에 따른 궁금증이 온다.
파라미터수와 그 성능 사이의 trade off에 관한 실험이 있었다면 더 좋았을 것 같다.
Introduction
Raw audio는 resolution이 크기 때문에 이를 모델링하는 일은 어렵다.
그래서 raw audio를 바로 모델링하는 대신, lower-resolution을 모델링하는 것으로 단순화할 수 있다.
본 논문은 mel-spectrogram을 audio로 바꾸는 방법을 제시한다.
제안하는 방법은 최초로 GAN을 이용한 non-autoregressive feed-forward convolutional architecture를 가진다.
The MelGAN Model
1. Generator
Architecture
Generator는 mel-spectrogram $s$를 입력으로 받고 raw waveform $x$를 출력으로 하는 fully convolutional feed-forward 네트워트다.
실험에 사용되는 mel-spectrogram은 $256 \times$ lower temporal resolution이기 때문에 input sequence를 upsample 하기 위해 transposed conv layer를 사용했다.
기존에 사용되던 GAN과 달리, 제안하는 generator는 입력으로 global noise vector를 사용하지 않는다.
왜냐하면 그렇게 했을 경우 waveform을 생성할 때 어려움이 생기는 것을 실험적으로 확인했기 때문이다.
Induced receptive field
Image는 가까이 있는 pixel끼리 induced receptive field에서 correlated 되어있기 때문에 Image를 만들 때 사용되는 CNN-based generator를 사용한다.
Audio timestep에서 long range correlation이 존재하기에 generator 구조에 inductive bias를 추가했다.
각 upsampling layer 뒤에 dilation이 있는 residual blocks를 추가함으로써 뒤에 있는 layer도 overlapping 한 input을 가지도록 했다.
Checkerboard artifacts
Deconvolution generator는 transposed conv layer에서 kernel-size와 stride가 세밀하게 정해지지 않았기 때문에 checkerboard artifacts가 존재한다.
이 문제는 (Donahue, C., McAuley, J., and Puckette, M. Adversarial audio synthesis. arXiv preprint arXiv:1802.04208, 2018b.)를 이용해 kernel-size와 stride를 잘 정함으로써 해결했다.
Dilation이 kernel-size의 power로 커지도록 했다.
Normalization technique
Weight normalization을 사용했다.
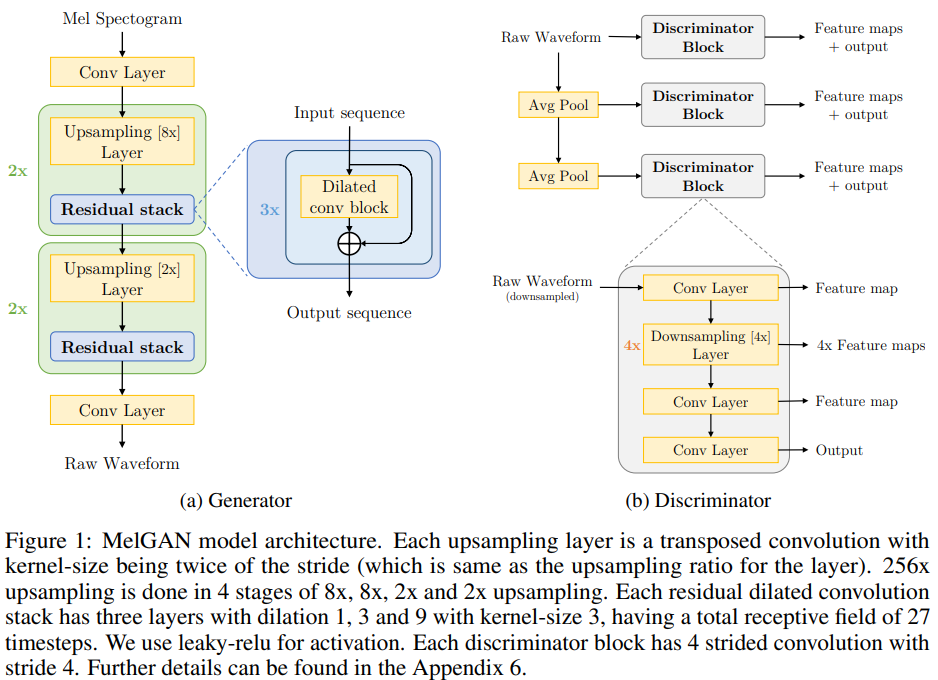
2. Discriminator
Multi-Scale Architecture
Discriminator 3개를 이용해 multi-scale architecture를 적용했다.
Average pooling을 이용해 각각 $\times 1, \times 1/2$, $\times 1/4$가 되도록 했다.
Window-based objective
각 discriminator들은 크기가 큰 kernel을 사용한 strided conv layer들로 구성된 Markovian window-based discriminator다.
기존의 GAN discriminator는 전제 audio를 이용해 분류한다면, window-based discriminator는 audio를 작게 잘라서 분류한다.
Window-based discriminator는 중요한 high frequency 구조를 더 빨리, 더 적은 파라미터로 잡아내며 다양한 길이의 audio에 적용할 수 있기 때문에 이를 사용했다.
Generator처럼 모든 layer에 weight normalization을 사용했다.
3. Training objective
GAN objective의 hinge loss 버전을 사용했다.
$\displaystyle \min_{D_k} \mathbb{E}_x \left[\min(0, 1-D_k(x)) \right] + \mathbb{E}_{s, z} \left[\min(0, 1 + D_k(G(s, z))) \right]$
$\displaystyle \min_G \mathbb{E}_{s, z} \left[ \sum_{k=1,2,3} -D_k(G(s, z))\right]$
$x$: raw waveform, $s$: mel-spectrogram, $z$: gaussian noise vector
Feature Matching
Generator를 학습시키기 위해 feature matching objective를 사용했다.
이것은 진짜 audio와 만들어진 audio 사이의 discriminator feature map 사이의 L1 distance를 최소화한다.
$L_{FM}(G, D_k) = \mathbb{E}_{x, s~p_{data}} \left[ \displaystyle \sum^T_{i=1} {1 \over N_i} || D_k^{(i)}(x) - D_k^{(i)}(G(s))||_1\right]$
최종 loss는 다음과 같다.
$\displaystyle \min_G \left(\mathbb{E}_{s,z} \left[\sum_{k=1,2,3} -D_k(G(s,z)) \right] + \lambda \sum^3_{k=1}L_{FM}(G,D_k) \right)$
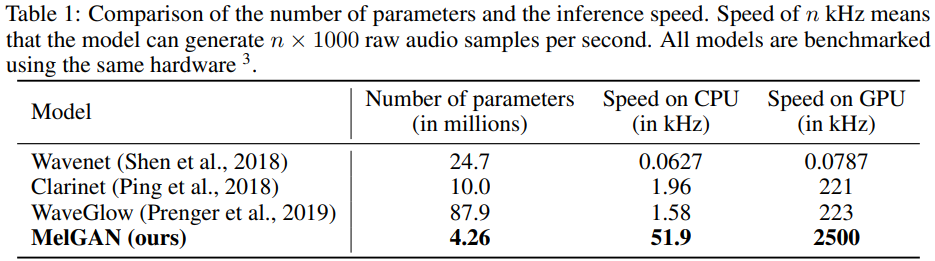
4. Number of oparameters and inference speed
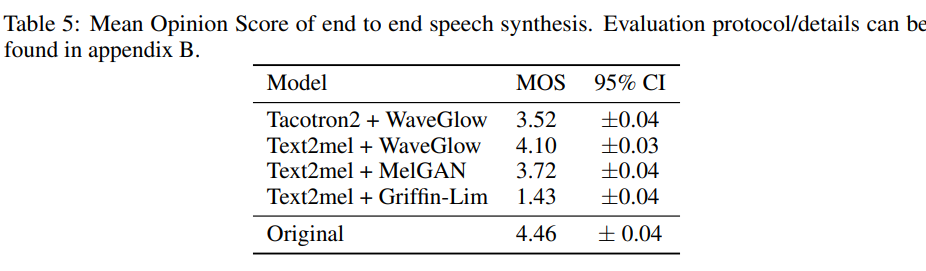
Results
Conclusion and future work
제안하는 MelGAN은 GAN-based 구조를 가지고 있으며, 가볍고, 속도도 빠르고, 그 성능 또한 뛰어나다.
Unconditional GAN 쪽으로 연구를 해보겠다.
Reference
Kumar, Kundan, et al. "MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis." Advances in Neural Information Processing Systems 32 (2019).


