
- Today
- Total
작심삼일
[VITS] Conditional Variational Autoencoder with Adversarial Learning forEnd-to-End Text-to-Speech (arXiv 21) 본문
[VITS] Conditional Variational Autoencoder with Adversarial Learning forEnd-to-End Text-to-Speech (arXiv 21)
yun_s 2021. 11. 11. 17:03My Opinion
TTS에서는 주로 text → mel, mel → wav의 두 단계로 나눠서 발화 음성을 생성한다.
물론 그동안 end-to-end 모델이 없던 것은 아니지만, 그 성능이 두단계로 이루어진 모델들보다 좋지 않았다.
하지만 이번에 발표된 VITS는 그 성능이 더 뛰어나, 거의 현재까지의 SOTA로 보인다.
이 모델은 Glow-TTS와 HiFi-GAN을 동시에 학습시킨 모델이라고 볼 수 있다.
이 전까지 이런 시도를 해본 사람이 없던 것은 아닐테니, 이렇게 안정적으로 학습을 시켜서 성능이 뛰어난 end-to-end 모델을 만든 것이 이 논문의 novelty다.
Glow-TTS, HiFi-GAN과의 다른점을 본다면, MAS를 그대로 사용할 수 없기 때문에 ELBO를 최대화하는 방식으로 MAS를 수정한 것 뿐이다.
Introduction
Text-to-speech(TTS)는 주어진 글을 발화로 바꾸는 시스템이다.
FastSpeech 2s나 EATS는 end-to-end 시스템이었으나 두 단계로 나뉜 모델들보다 성능이 좋지 않았다.
본 논문에서는 두 단계로 이루어진 모델들보다 뛰어난 parallel end-to-end TTS를 소개한다.
Variational autoencoder(VAE)를 이용해 TTS의 두 모듈을 연결했다.
좋은 품질의 발화음성을 생성하기 위해 conditional prior distribution에 normalizing flow를 적용하고, waveform 영역에서 adversarial training을 적용했다.
Audio를 잘 만들기 위해서는 주어진 문장이 다양하게 발화될 수 있도록 one-to-many를 할 수 있어야 한다.
이를 해결하기 위해 stochastic duration predictor를 이용했다.
Method
Variational Inference
1. Overview
VITS는 log-likelihood ELBO를 최대화하는 conditional VAE라고 표현할 수 있다.
logpθ(x|c)≥Eqϕ(z|x)[logpθ(x|z)−logqϕ(z|x)pθ(z|c)]
pθ(z|c): prior distribution fo the latent variables z given condition c
pθ(x|z): likelihood function of a data point x
qϕ(z|x): approximate posterior distribution
Train loss는 reconstruction loss(logpθ(x|z))와 KL divergence(logqϕ(z|x)−logpθ(z|c))의 합으로 이루어진 negative ELBO다.
2. Reconstruction loss
우리는 raw waveform 대신 mel-spectrogram xmel을 이용해 reconstruction loss를 사용했다.
디코더로 latent variables z를 waveform domain ˆy로 upsampling한 후, ˆy를 mel-spectrogram domain ˆxmel로 바꿨다.
Reconstruction loss는 predicted mel-spectrogram과 target mel-spectrogram 사이의 L1 loss다.
Lrecon=||xmel−ˆxmel||1
사람이 듣기에 더 좋은 음성을 만들기 위해 mel-scale을 사용했다.
3. KL-Divergence
Prior encoder c의 input은 입력 문장에서 추출한 phonemes ctext, 그리고 phonemes와 latent variable간의 alignment A로 구성된다.
Alignment에는 정답이 없기 때문에 각 학습 iteration마다 alignment를 측정했다.
우리는 posterior encoder에 더 좋은, high-resolution 정보를 주고자 했다.
그래서 mel-spectrogram 대신 target speech xlin의 linear-scale spectrogram을 사용했다.
Lkl=logqϕ(z|xlin)−logpθ(z|ctext,A)
z qϕ(z|xlin)=N(z;μϕ(xlin),σϕ(xlin))
Prior와 posterior encoder를 표현하기 위해 factorized normal distribution을 사용했다.
실제같은 음성을 만들기 위해서는 prior distribution의 expressiveness를 늘리는 것이 중요하다는 것을 발견했다.
그래서 factorized normal prior distribution에 normalizing flow fθ를 적용했다.
pθ(z|c)=N(fθ(z);μθ(c),σθ(c))|det∂fθ(z)∂z|,c=[ctext,A]
Alignment Estimation
1. Monotonic alignment search
입력 문장과 목표로 하는 발화 간의 alignment A를 측정하기 위해 Monotonic Alignment Search(MAS)를 사용했다.
MAS는 normalizing flow f를 사용해서 data의 likelihood를 최대화하는 방법이다.
A=argmaxˆxlogp(x|ctext,ˆA)=argmaxˆAlogN(f(x);μ(ctext,ˆA),σ(ctext,ˆA))
우리는 log-lokelihood가 아닌 ELBO를 사용하기 때문에 MAS를 그대로 사용하는 것은 어려웠다.
그래서 ELBO를 최대화하는 방식으로 MAS를 수정했다.
argmaxˆAlogptheta(xmel|z)−logqphi(z|xlin)pθ(z|ctext,ˆA)=argmaxˆAlogpθ(z|ctext,ˆA)=logN(fθ(z);μθ(ctext,ˆA),σθ(ctext,ˆA))
2. Duration prediction from text
계산된 alignment를 이용해 sum함으로써(∑jAi,j) input token di의 duration을 계산할 수 있다.
사람이 한 것 같은 발화를 만들기 위해 stochastic duration predictor를 설계했다.
Stochastic duration predictor는 maximum likelihood estimation을 기반으로 학습된 flow-based 모델이다.
하지만 maximum likelihood estimation을 바로 적용하는 것은 어렵다.
왜냐하면 각 input의 duration이 discrete integer이기 때문에 continuous normalizing flow에서 사용하기 위해서는 dequantization이 필요하고, scalar이기 때문에 high-dimensional transformation을 할 수 없기 때문이다.
이 문제를 해결하기 위해 variational dequantization과 variational data augmentation을 적용했다.
더 자세히 말하자면, duration sequence d와 같은 time resolution과 dimension을 가지고 있는 random variables u,v를 만들었다.
u의 범위를 [0,1)로 제한해 d−u가 positive real number가 되도록 하고, v,d를 channel-wise하게 concatenate해서 higher dimensional latent를 표현할 수 있게 했다.
결과적으로 phoneme duration의 log-likelihood의 lower bound는 다음과 같다.
logpθ(d|ctext)≥Eqϕ(u,v|d,ctext)[logpθ(d−u,v|ctext)qphi(u,v|d,ctext)]
Adversarial training
Adversarial training을 위해 the least-squares loss를, generator의 학습을 위해 additional feature matching loss를 사용했다.
Ladv(D)=E(y,z)[(D(y)−1)2+(D(G(z)))2]
Ladv(G)=Ez[(D(G(z))−1)2]
Lfm(G)=E(y,z)[T∑l=11Nl||Dl(y)−Dl(G(z))||1]
T: the total number of layers in the discriminator
Dl: the feature map of the l-th layer of the discriminator with Nl number of features
Final loss
Lvae=Lrecon+Lkl+Ldur+Ladv(G)+Lfm(G)
Model Architecture

1. Posterior encoder
Posterior encoder에는 WaveGlow와 Glow-TTS에 사용된 non-casual WaveNet residual blocks을 사용했다.
WaveNet residual block은 gated activation unit과 skip connection이 포함된 dilated conv로 이루어져있다.
그 뒤의 linear projection layer는 normal posterior distribution의 mean과 variance를 계산한다.
2. Prior encoder
Prior encdoer는 input phonemes ctext와 normalizing flow $$f_{\theta}를 다루는 text encoder로 구성되어있다.
Text encoder는 absolute positional encoding 대신, relative positional 표기방법을 사용하는 transformer encoder이다.
이를 통해 ctext에서 htext를 얻을 수 있다.
Normalizing flow는 affine coupling layers로 이루어져있는데, 이를 단순하게 하기 위해 Jacobian determinant를 사용해 normalizing flow를 volume-preserving transformation했다.
3. Decoder
Decoder는 Hifi-GAN의 generator를 사용했다.
4. Discriminator
Hifi-GAN의 multi-period discriminator의 discriminator의 구조를 따라했다.
5. Stochastic duration predictor
Stochastic duration predictor는 htext로부터 phoneme duration을 계산한다.
Dilated하며 depth-separable한 conv layers로 residual block를 쌓았고, neural spline flows를 적용했다.
Neural spline flows는 비슷한 수의 파라미터로 affine coupling layer보다 transformation expressiveness를 향상시킨다.
Experiments
Optimizer: AdamW (β1=0.8,β2=0.99,λ=0.01)
Learning rate: 2×10−4
Results
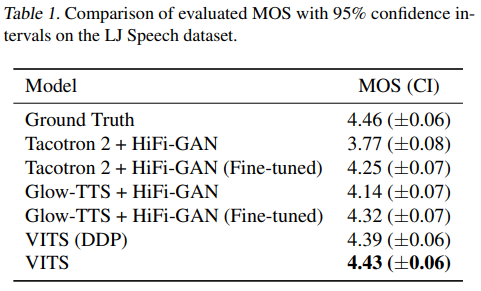
Conclusion
본 논문에서는 end-to-end TTS 모델인 VITS를 소개한다.
이 모델은 자연스러운 발화 음성을 생성한다.
Reference
Kim, Jaehyeon, Jungil Kong, and Juhee Son. "Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech." arXiv preprint arXiv:2106.06103 (2021).


