
- Today
- Total
작심삼일
[LaMa 리뷰] Resolution-robust Large Mask Inpainting with Fourier Convolutions (CVPR 22) 본문
[LaMa 리뷰] Resolution-robust Large Mask Inpainting with Fourier Convolutions (CVPR 22)
yun_s 2022. 8. 10. 16:15My Summary & Opinion
Introduction
Image impainting 문제를 풀기 위해서는 이미지를 잘 이해하고 잘 합성하는 것이 필요하다.
Inpainting을 학습시킬때는 주로 real image를 자동으로 masking한 큰 데이터셋을 사용한다.
이미지의 global structure를 이해하기 위해서는 큰 receptive field가 필요하다.
하지만 convolutional architecture는 충분히 큰 receptive field를 가지지 못한다는 문제가 있다.
이런 문제를 해결한 모델인 LaMa를 소개한다.
LaMa의 특징은 크게 세가지로 볼 수 있다.
1. Fast Fourier Convolution(FFC)를 사용했다.
2. 큰 receptive field를 가진 segmentation network 기반 perceptual loss를 사용했다.
3. 효과적으로 mask를 생성해, 위 두가지를 효과적으로 사용하게 했다.
Method
1. Global context within early layers
우리는 receptive field를 최대한 크게 갖는 구조를 설계하고자 했다.
Resnet과 같이 기존에 사용되던 convolution model은 receptive field가 느리게 커진다는 문제가 있었다.
이 문제를 해결하기 위해 우리는 FFC를 사용했다.
Fast Fourier convolution (FFC) [다른 글 참조: FFC 리뷰]
FFC는 early layer에서도 global context를 사용하기 위해 고안되었다.
FFC는 채널을 1) 기존의 conv를 사용하는 local branch, 2) real FFT를 사용하는 global branch, 두가지로 나눈다.
Inverse real FFT를 사용하기 때문에 output이 항상 real이게 된다.
FFC는 다음과 같이 행해진다.
1) Real FFT2d를 input tensor에 적용하고, real part와 imaginary part를 합친다.


2) frequency domain에서 conv를 적용한다.

3) Spatial structure로 복원하기 위해 inverse transform을 진행한다.

아래 그림이나 [FFC 리뷰]를 참고하면 이해가 쉽다.
The power of FFCs
FFC는 미분 가능하며 기존 conv대신 교체하기 쉽다. 아무것도 수정하지 않아도 된다.
그러면서 model로 하여금 global context를 잘 이해하도록 한다.

2. Loss functions
High receptive field perceptual loss
Supervised loss를 그대로 사용하면 mask된 부분에 대한 정보가 없기 때문에 blur된 결과가 나오게 된다.
이와 달리 perceptual loss는 predicted 이미지와 target 이미지에서 pretrained network$\phi()$로 뽑은 feature들 간의 거리를 계산한다.
그렇기 때문에 pretrained network를 어떤 것을 사용하느냐가 중요하다.
우리는 high receptive field를 사용하는 model$\phi_{HRF}()$를 사용했다.
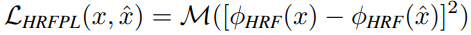
$[ - ]^2$: element-wise operation, $M$: sequential two-stage mean operation
$\phi_{HRF}$는 Fourier나 Dilated conv를 사용한 모델이 될 수 있다.
Pretext problem
Perceptual loss에 사용될 네트워크를 고르는 문제는 중요하다.
만약 segmentation model을 사용하면 object와 같은 high-level 정보에만 치중되어있을 것이며, classification model을 사용하면 texture와 같은 정보에만 치중되어있을 것이다.
Adversarial loss
Detail이 자연스러워보이게 하기 위해 adversarial loss를 사용했다.
Discriminator $D$로 하여금 patch-level로 동작하게 했다.
Mask된 영역이 있는 patch만 "fake"라 했다.
generated image의 mask가 되지 않은 부분조차 "real"이라고 정했다.
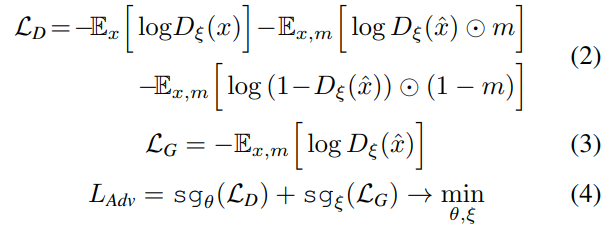
$m$: mask, $\hat x = f_{\theta}(x')$: impainting result
The final loss function
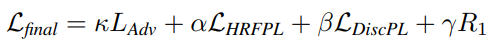
$R_1$: gradient penalty, $L_{DiscPL}$: discriminator-based perceptual loss (feature matching loss)
3. Generation of masks during training
큰 mask를 사용했는데, 이 mask를 생성하기 위해 wide masking, box masking을 진행했다.
예시는 아래 그림과 같다.
이렇게 데이터를 만들 때, 마스크가 이미지의 50%를 넘어가는 것은 제외했다.
나중에 실험했을 때, 큰 mask를 사용했을 때 성능이 더 좋았다.

Experiments
LaMa는 파라미터 수는 더 적지만 더 좋은 성능을 보인다.
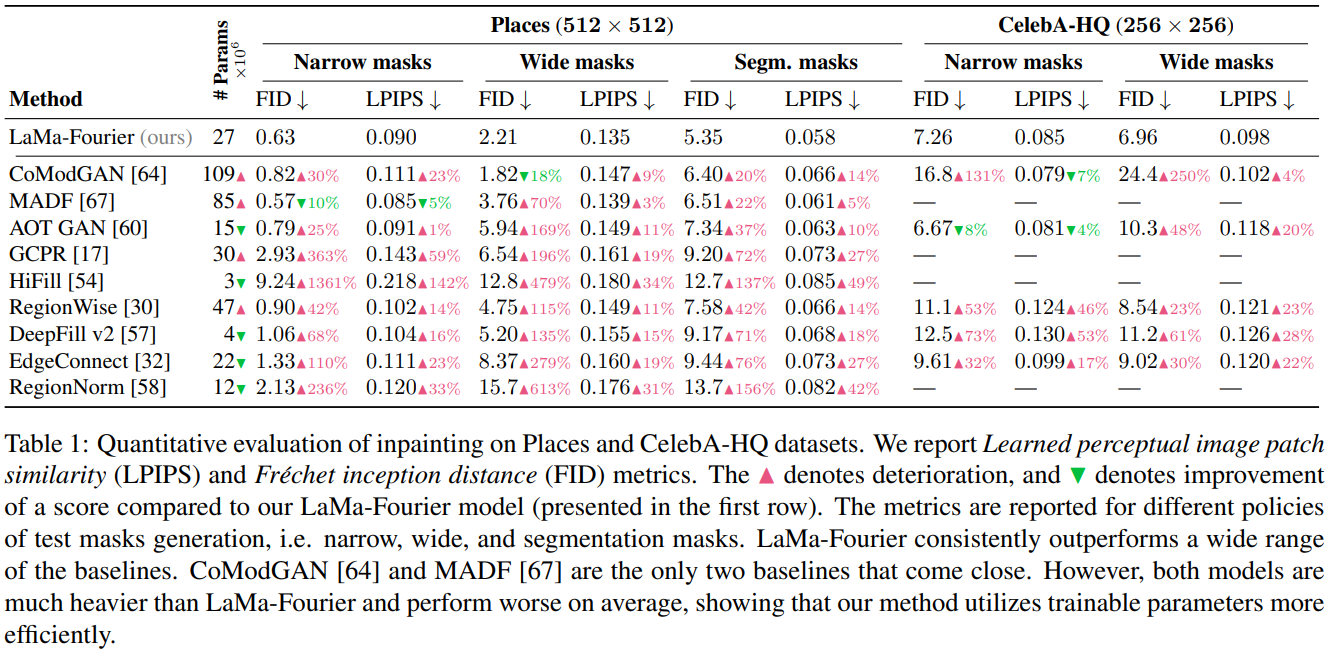
FFC를 사용했을 때 그 성능이 더 좋아졌다.

Reference
Suvorov, Roman, et al. "Resolution-robust large mask inpainting with fourier convolutions." Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2022.
'Deep Learning > Vision' 카테고리의 다른 글
| [VQ-GAN 리뷰] Taming Transformers for High-Resolution Image Synthesis (0) | 2023.09.13 |
|---|---|
| [FFC 리뷰] Fast Fourier Convolution (NIPS 20) (0) | 2022.08.08 |
| [YOLOv4 리뷰] Optimal Speed and Accuracy of Object Detection (arXiv 20) (0) | 2022.08.07 |
| [YOLOv3 리뷰] YOLOv3: An Incremental Improvement (arXiv 18) (0) | 2022.08.04 |
| [YOLOv2 리뷰] YOLO9000: Better, Faster, Stronger (CVPR 17) (0) | 2022.08.02 |



