
반응형
Notice
Recent Posts
Recent Comments
- Today
- Total
작심삼일
[VQ-GAN 리뷰] Taming Transformers for High-Resolution Image Synthesis 본문
Deep Learning/Vision
[VQ-GAN 리뷰] Taming Transformers for High-Resolution Image Synthesis
yun_s 2023. 9. 13. 20:59728x90
반응형
Introduction
Key Insight
- CNN과 transformer의 장점을 살리자!
- CNN
- local한 영역에서 강점을 가짐
- Transformer
- Long-range의 관계를 잘 학습 함
- CNN
Approach
이미지를 pixel 말고 codebook으로 나타내보자
Learning an Effective Codebook if Image Constituents for Us in Transformers
왜 Codebook을 사용하는가
- 이미지 영역에 Transformer 구조를 적용하려면, 이미지를 sequence형태로 나타내야 함
- 이미지 $x \in R^{H \times W \times 3}$ $\rightarrow$ codebook의 원소 $z_q \in R^{h \times w \times n_z}$들로 구성
- $n_z$: dimensionality of codes
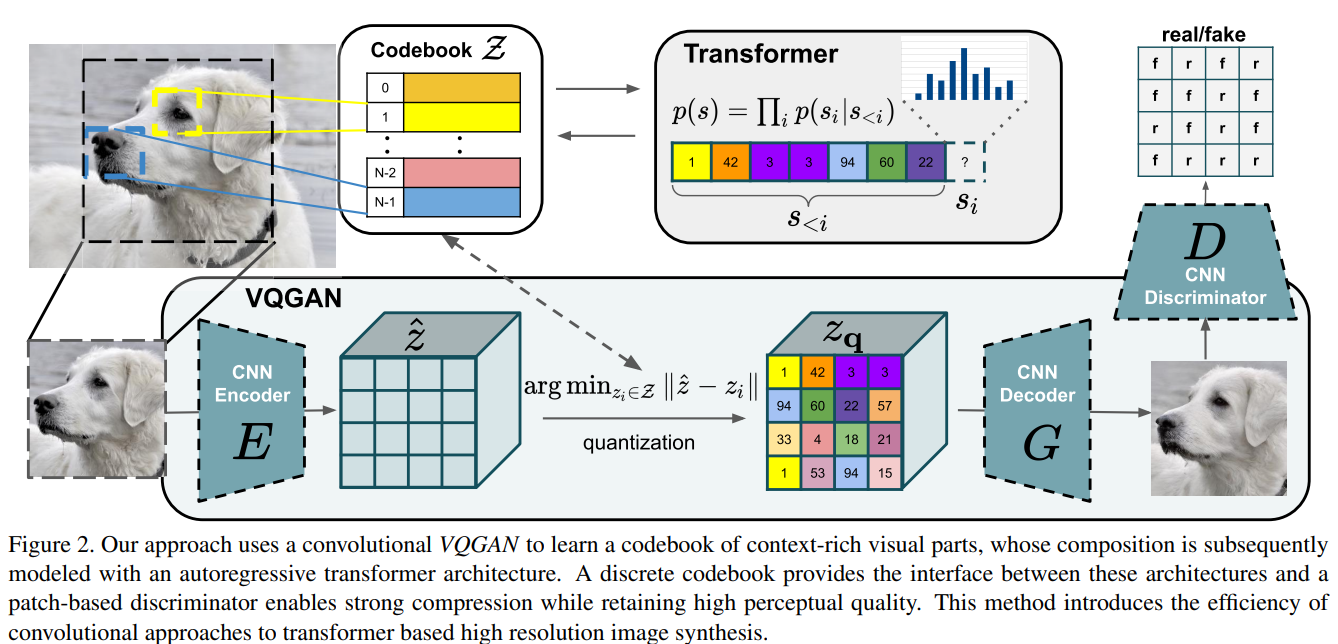
어떻게 Codebook을 사용하는가
- Encoder $E$와 Decoder $G$로 Convolutional model을 학습
- 해당 convolutional model은 이미지를 codebook 안의 code로 나타내는 법을 학습
- Loss function
- reconstruction loss + embedding loss + commitment loss

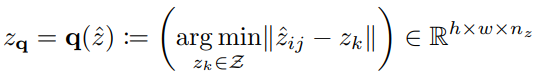
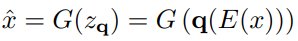
Learning a Perceptually Rich Codebook
압축할 때 생기는 한계를 극복하고, 더 알찬 codebook 만들기 위해 다음과 같이 GAN Loss를 사용함

Learning the Composition of Images with Transformers
Latent Transformers
- 이미지는 codebook의 인덱스로 변환될 수 있음
- $s_{ij}=k$ such that $(z_q)_{ij}=z_k$
- 이미지 생성 문제는 이제 auto-regressive한 next-index를 예측하는 문제로 바꿔서 생각할 수 있음
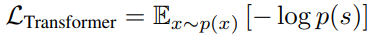

Conditioned Synthesis
- 그에 맞는 다른 codebook $Z_c$를 학습
-
- 주어진 정보 $c$로 sequence의 likelihood를 학습하기
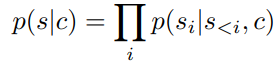
Generating High-Resolution Images
- Transformer는 sequence length가 제한되어 있으니 downsampling을 진행하자
- 어떻게? Sliding window 방식으로

Reference
Esser, Patrick, Robin Rombach, and Bjorn Ommer. "Taming transformers for high-resolution image synthesis." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021.
728x90
반응형
'Deep Learning > Vision' 카테고리의 다른 글
| [LaMa 리뷰] Resolution-robust Large Mask Inpainting with Fourier Convolutions (CVPR 22) (0) | 2022.08.10 |
|---|---|
| [FFC 리뷰] Fast Fourier Convolution (NIPS 20) (0) | 2022.08.08 |
| [YOLOv4 리뷰] Optimal Speed and Accuracy of Object Detection (arXiv 20) (0) | 2022.08.07 |
| [YOLOv3 리뷰] YOLOv3: An Incremental Improvement (arXiv 18) (0) | 2022.08.04 |
| [YOLOv2 리뷰] YOLO9000: Better, Faster, Stronger (CVPR 17) (0) | 2022.08.02 |
'Deep Learning/Vision' Related Articles
more




Comments