
- Today
- Total
작심삼일
[SRGAN리뷰] Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network (CVPR 17) 본문
[SRGAN리뷰] Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network (CVPR 17)
yun_s 2021. 4. 25. 12:11My Summary & Opinion
MSE처럼 기존의 pixel-wise 한 방식은 high-frequency 성분을 제대로 살리지 못한다.
PSNR과 SSIM도 human visual system과 비례하는 것이 아니다.
이 논문에서는 이런 문제들에 대한 해법으로 GAN을 사용해서 더 realistic한 이미지를 생성하도록 했다.
또한, loss도 기존의 MSE가 아닌 perceptual loss(content loss + adversarial loss)를 사용했다.
MSE는 평균을 내는 방식이므로 over-smoothing 된다.
하지만 content loss는 VGG network의 feature map을 이용한 euclidean distance를 사용하기 때문에 pixel의 정확도보다 perceptual similarity에 좀 더 집중했다.
MSE로 학습하지 않았기 때문에 PSNR이나 SSIM은 더 낮지만, 사람이 봤을 때 더 그럴듯한 이미지가 나온다.MOS 점수도 제일 높다.
Introduction
SR 문제를 어렵게 하는 것은 reconstruct 된 SR 이미지의 detail 한 부분이다.
SR 알고리즘들은 보통 HR 이미지와 GT 사이의 MSE를 최소화하는 방식으로 학습된다.
MSE를 최소화하는 방식은 measurement로 자주 사용되는 PSNR을 최대화하는 방식처럼 편하다.
하지만 MSE와 PSNR은 pixel-wise difference로 정의되기 때문에 detail 한 부분이 아닌, 큰 차이에만 집중되어있다.
아래의 그림을 보면 PSNR이 높은 것이 항상 더 좋은 SR result인 것은 아니다.
이 논문에서는 VGG network의 high-level feature map과 discriminator를 활용한 perceptual loss를 제안한다.

1. Related Work
1) Image super-resolution
요즘은 CNN-based algorithm이 SR 영역에서 뛰어난 성능을 보인다.
2) Design of convolutional neural networks
네트워크가 깊을수록 학습은 어렵지만 학습이 잘 된다면 성능이 높을 것으로 예상된다.
깊은 네트워크를 학습시키기 위해 Batch-Normalization(BN), residual block, skip-connection이 주로 사용된다.
SISR 영역에서는 upscaling filter를 학습시키는 것이 성능도 높이고 속도도 빠르다는 것을 알아냈다. (FRCNN, ESPCN)
3) Loss functions
MSE와 같은 pixel-wise loss function들은 high-frequency detail을 잘 복원하지 못한다.
이 문제를 Generative Adversarial Networks(GAN)을 이용해 해결하고 있다.
2. Contribution
High-upscaling factor(4배)에서 PSNR과 SSIM으로 측정했을 때 SOTA인, MSE로 학습한 16 layers 짜리 SRResNet을 제안한다.
새로 정의한 perceptual loss로 학습 된 GAN-based network인 SRGAN을 제안한다.
Mean Opinion Score(MOS)로 측정했을 때 SRGAN이 SOTA다.
Method
ILR: low-resolution image, IHR: high-resolution image, ISR: super-resolved image
ISR의 크기: W×H×C, IHR & ISR의 크기: rW×rH×rC
1. Adversarial network architecture
minθGmaxθDEIHR ptrain(IHR)[logDθD(IHR)]+EILR pG(ILR)[log(1−DθD(GθG(ILR)))]
이 수식의 의미는 super-resolve된 이미지와 real 이미지를 구분하도록 학습된 discriminator D를 속이는 generative model G를 학습시키는 것이다.
이런 접근 방식을 통해 generator는 real 이미지와 비슷하게 만들 수 있다.
위 그림을 참고하면, generator network G의 핵심은 B개의 residual block이다.
좀 더 자세히 살명해보면, 3×3 kernel을 사용하는 conv layer가 만드는 64 feature maps 뒤에 BN과 PReLU가 차례로 붙는다.
ESPCN의 sub-pixel conv layer를 이용해서 이미지를 up-sampling 한다.
Discriminator network D에서는 LeakyReLU(α=0.2)를 사용했고, max-pooling은 지양했다.
D는 위 수식 중 maximization 문제를 풀도록 학습된다.
3×3 kernel을 사용하는 conv layer 8개로 구성되는데, feature map의 수는 VGG network처럼 64부터 512까지 커진다.
Feature map 수가 늘어날 때마다 image resolution을 줄이기 위해 strided conv를 사용했다.
마지막의 512 feature maps 뒤에는 dense layer 두 개, 그리고 classification을 위한 sigmoid가 붙는다.
2. Perceptual loss function
Perceptual loss는 content loss(lSRX)와 adversarial loss의 weighted sum으로 정의된다.
lSR=lSRX+10−3lSRGen
1) Content loss
MSE는 pixel-wise 하기 때문에 종종 texture를 너무 smoothing 해서 high-frequence 부분들이 없어진다.
그래서 pixel-wise 한 loss를 사용한 대신에 perceptual similarity에 더 가까운 loss function을 사용했다.
ϕi,j는 VGG19 network에서 j번째 conv(와 activation) 뒤, i번째 max pooling layer 전의 feature map을 말한다.
VGG loss는 reconstructed image GθG(ILR)와 IHR의 euclidean distance로 정의된다.
lSRVGG/i,j=1Wi,jHi,jWi,j∑x=1Hi,j∑y=1(ϕi,j(IHR)x,y−ϕi,j(GθG(ILR))x,y)2
2) Adversarial loss
Generative loss lSRGen은 모든 training sample에 대한 discriminator DθD(GθG(ILR))의 확률로 정의된다.
lSRGen=N∑n=1−logDθD(GθG(ILR))
학습을 더 쉽게 하기 위해 log[1−DθD(GθG(ILR))] 대신 DθD(GθG(ILR))를 최소화하도록 학습했다.
Experiments

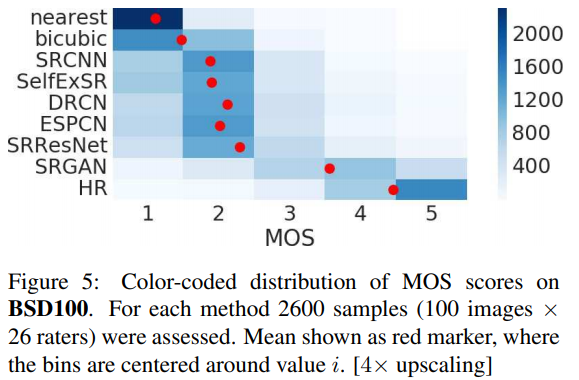
Discussion and future work (Conclusion에도 같은 내용)
MOS test를 통해 SRGAN의 엄청난 성능을 확인했다.
PSNR이나 SSIM과 같은 measure들은 human visual system과 맞지 않는다는 것을 보였다.
SR 문제에 대한 Photo-realistic 한 해법은 content loss다.
Reference
Ledig, Christian, et al. "Photo-realistic single image super-resolution using a generative adversarial network." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.



