
- Today
- Total
작심삼일
[REDNet 리뷰] Residual Encoder-Decoder Network (NIPS 16) 본문
[REDNet 리뷰] Residual Encoder-Decoder Network (NIPS 16)
yun_s 2021. 4. 23. 16:26Image Restoration Using Very Deep Convolutional Encoder-Decoder Networks with Symmetric Skip Connections
My Summary & Opinion
RED-Net에서 계속 반복적으로 말하고 있는 두 가지 특징이 있다.
첫째, convolution과 deconvolution을 symmetric 하게 쌓았다는 점이고,
둘째, symmetric 하게 쌓았으니 그에 대응하는 conv와 deconv 사이에 skip-connection을 사용한 것이다.
Conv와 deconv를 symmetric 하게 쌓은 것은 인코더-디코더의 역할을 한다.
Skip-connection은 다른 논문에서도 그렇듯이 feature map을 pass 시켜줘서 detail을 살리고, gradient vanishing 문제를 해결한다.
이런 트릭들을 자주 사용하는 요즘은 그렇게 새로워 보이지 않지만, 이 논문이 16년도 NIPS에 나왔는데도 이런 트릭들이 계속 사용되는 것을 보면 한 번쯤 봐 두면 괜찮은 논문인 것 같다.
Introduction
SR문제에 대한 해법으로 Deep Neural Network(DNN)이 엄청난 성능을 보이고 있지만 아직 의문점들이 있다.
네트워크를 깊게 쌓을수록 성능이 좋아지는가?
다양한 정도의 이미지 손상도를 다룰 수 있는 단순하고 깊은 모델을 설계할 수 있는가?
위의 질문들을 생각하며 Residual Encoder-Decoder Network(REDNet)을 설계했다.
REDNet의 특성은 다음과 같이 정리할 수 있다.
Convolution & Deconvolution layer가 symmetric 하게 이루어진 깊은 네트워크 구조를 가지고 있다.
Convolution layer는 corruption을 없애면서 encoding 하는 feature extractor의 역할을 하고, deconvolution layer는 decoding을 통해 이미지 detail을 추출하는 역할을 한다.
Convolution & Deconvolution layer 사이에 skip connection을 추가함으로써 학습이 더 효과적으로 잘 된다.
실험 결과를 보면 우리 네트워크가 image denoising & SR에서 SOTA이다.
Very deep RED-Net for Image Restoration

1. Architecture
전체적인 구조는 전부 convolutional, deconvolutional 하다.
Convolution layer는 corruption을 없애면서 encoding 하는 feature extractor의 역할을 하고, deconvolution layer는 decoding을 통해 이미지 detail을 추출하는 역할을 한다.
Skip-connection은 convolutional layer와 그에 대응하는 deconvolutional layer 사이에 더한다.
Convolutional feature map은 deconvolutional feature map과 element-wise 하게 바로 더해진다.
Kernel 크기는 $3 \times 3$이고, $20 ~ 30$ layers, $64$ feature maps를 사용했다.
1) Deconvolution decoder
Convolutional layer와 반대로 deconvolutional layer는 single input & multiple output이다.
학습 가능한 up-sampling layers로 이해하면 쉽다.
네트워크의 layer를 지날 때마다 noise는 점차적으로 감소하는데, 이와 동시에 이미지 detail도 없어질 수 있다.
하지만 RED-Net은 이런 detail을 보존하기 위해 deconvolution layer를 사용했다.
또한, 이런 구조를 통해 feature map의 크기를 줄여, 보다 제한된 computing power에서도 사용할 수 있다.
2) Skip connections
깊지 않은 네트워크에서는 deconvolution이 detail을 복원하지만, 네트워크가 깊어지거나 max pooling과 같은 연산을 사용하면 deconvolution이 제 역할을 하지 못하는 것을 발견했다. (첫 번째 문제)
그렇다면 이미 많은 detail들이 convolution 과정 중에 사라진 것이 아닐까?
두 번째 문제는 네트워크가 깊어질수록 gradient vanishing 문제가 자주 발생해 학습이 어려워진다는 것이다.
이 문제들을 해결하기 위해 skip connection을 사용했다.
Convolution 과정 중에 detail들이 사라지는 것은 skip connection을 통해 detail이 들어있는 feature map을 바로 보낼 수 있다.
또한, 다른 논문들에서도 볼 수 있다시피 back-propagation을 진행할 때도 도움이 된다.
Input $X$에서 바로 output $Y$를 학습하도록 하지 않고, 그 차이 $F(X) = Y - X$를 학습하도록 했다.
2. Discussions
이 부분에서는 실험적으로 이 논문의 concept이 맞다는 것을 보여준다.
아래 3가지 실험을 통해 이 네트워크의 성능이 좋다는 것을 증명하기 때문에 길게 적지 않겠다.
1) Training with symmetric skip connections
2) Comparison with deep residual networks
3) Dealing with different levels of noises/corruption
3. Training
| Loss function | Optimizer | Learning rate | Input patch size |
| MSE | Adam | $10^{-4}$ | $50 \times 50$ |
4. Testing
Data augmentation 진행
Experiments
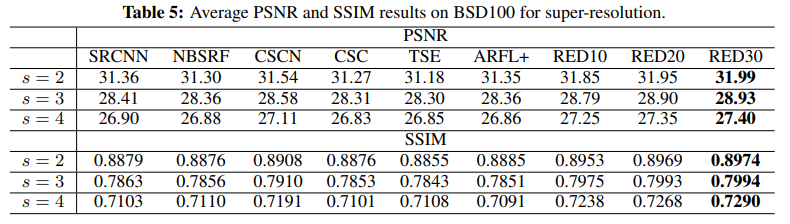
Conclusions
Convolution & deconvolution을 사용해 image restoration에서 성능을 보이는 네트워크를 소개한다.
Image detail을 살리고 gradient vanishing 문제를 해결하기 위해 skip-connection을 사용해서, 깊은 네트워크에서도 잘 된다.
실험적으로도 이 사실을 확인할 수 있다.
Reference
Mao, Xiao-Jiao, Chunhua Shen, and Yu-Bin Yang. "Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections." Proceedings of the 30th International Conference on Neural Information Processing Systems. 2016.



