
- Today
- Total
작심삼일
[DRRN 리뷰] Image Super-Resolution via Deep Recursive Residual Network (CVPR 17) 본문
[DRRN 리뷰] Image Super-Resolution via Deep Recursive Residual Network (CVPR 17)
yun_s 2021. 7. 22. 11:19My Summary & Opinion
이맘때의 논문들은 다양한 형태로 residual을 사용하는 방식들이 많았다.
DRRN도 그 중 하나다.
이 residual unit 구조를 찾기 위해 많은 실험들을 했을 것이고, 그 중 하나로 이 구조가 뽑혔을 것이라 짐작된다.성능이 뛰어나고, 깊이가 깊어도 안정적으로 학습이 된다는 것이 이 모델의 장점이라고 생각한다.
Introduction
SISR는 LR로부터 HR를 만드는 오래된 vision problem이다.
요즈음 powerful한 Deep Learning(DL) 모델들, 특히 CNN 이 주로 쓰였다.
여러 모델들을 살펴보면 SR에서는 "the deeper the better"이다.
그 성능은 뛰어나지만, 깊은 네트워크는 많은 파라미터들이 필요하다.
Compact한 모델과 비교하면, 큰 모델들은 더 많은 저장 공간이 필요하기 때문에 mobile에 적용하기는 힘들다.
이 문제를 해결하기 위해 Deep Recursive Residual Network(DRRN)을 제안한다.
아래 두 개가 DRRN의 큰 특징이다.
1) Both global and local learning
2) Recursive learning
Related Work
1. ResNet
ResNet은 깊은 네트워크가 더 잘 학습되게 하기 위해 residual learning을 사용한 것이다.
2. VDSR
ResNet이 몇 개의 층에만 residual learning을 사용한 것과 달리, VDSR은 GRL을 사용했다.
GRL은 input LR과 output HR 사이에 residual learning을 사용한 것이다.
3. DRCN
DRCN은 층을 더 쌓을수록 파라미터가 더 많이 필요하고, 더 쉽게 overfit한다는 점에서 착안했다.
이 문제를 해결하기 위해 recursive layer를 사용해서 recursion동안 파라미터 수가 증가하지 않도록 했다.
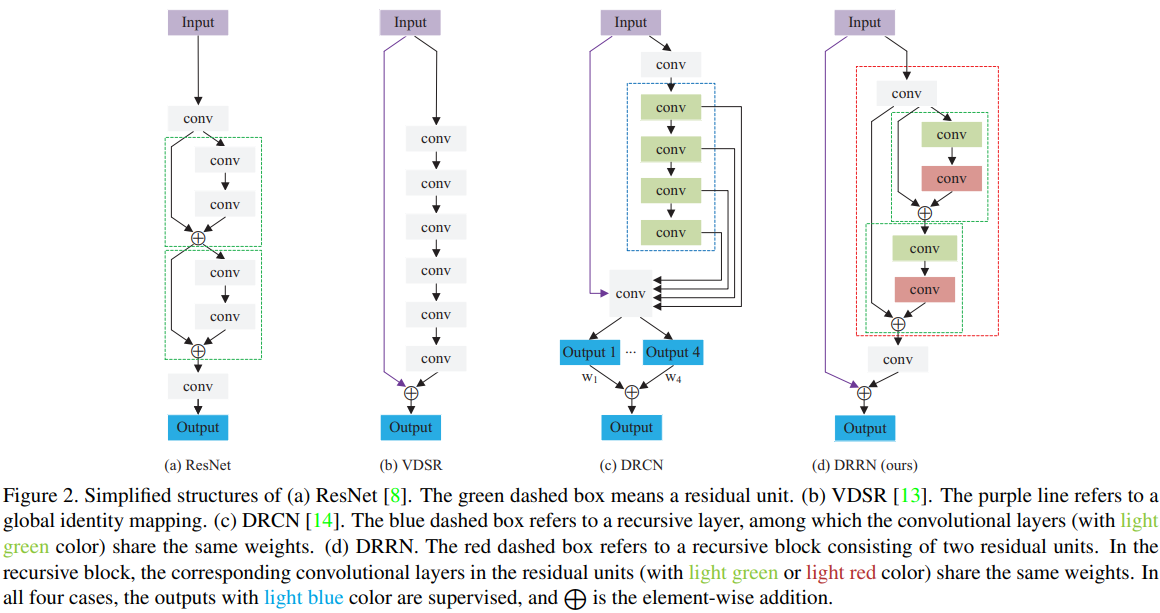
Deep Recursive Residual Network
1. Residual Unit
ResNet에서는 BN과 ReLU같은 activation function들이 weight layer 뒤에 온다.
이런 "post-activation"과 달리, weight layer 전에 activation을 진행하는 "pre-activation" 구조를 사용했다.
연구에 따르면 pre-activation을 사용하면 post-activation을 사용했을 때보다 학습이 더 잘되고 성능도 더 뛰어나다고 한다.
Pre-activation의 기본 구조는 다음과 같다.
$H^u = F(H^{u-1}, W^u) + H^{u-1}$
$H^{u-1}, H^u$: input and output of the $u$-th residual unit
$F$: residual function
이 구조를 그대로 사용하지 않고, identity branch와 residual branch의 input이 다르게 되도록 했다.
(identity branch는 위 그림(fig. 2)의 (d)에서의 초록색 점선 박스다.)
High complex feature를 잘 학습하게 하기 위해 residual path를 사용하고, gradient backpropagation이 잘 되게 하기 위해 identity path를 사용했다.
그 결과 우리가 사용한 residual unit은 다음과 같다.
$H^u = G(H^{u-1}) = F(H^{u-1}, W) + H^0$
$G$: function of residual unit
$H^0$: the result of the first conv layer inthe recursive block
2. Recursive block
Recursive block은 아래 그림(fig. 4)와 같다.

3. Network Structure
제안하는 네트워크, DRRN은 residual block(RB)를 층층히 쌓아 만들었다.
DRRN은 파라미터 두 개가 존재하는데, 하나는 RB의 수를 나타내는 $B$이고, 다른 하나는 각 RB 안의 residual unit의 수를 나타내는 $U$이다.
Experiments
1. Implementation Details
| Data argumentation | Patch size | Optimizer | Learning rate |
| rotation & flip & scale | $31 \times 31$ | SGD | $0.1$ |
2. Study of B and U
"the deeper the better"라는 말처럼 B와 U를 키울수록 그 성능이 높아졌다.

3. Comparision with State-of-the-Art Models
제일 좋다.

4. Discussions
Local Residual Learning
LRL을 사용하면 모든 깊이에서 성능이 올라간다.
Recursive Learning
Weight-shared DRRN이 성능도 더 좋고 overfitting에도 더 강했다.
Multi-Path Structure
같은 깊이와 같은 파라미터 수를 가지고 있는 모델을 비교했을 때, multi-path를 사용한 모델의 PSNR이 제일 높다.
Deep vs. Shallow
깊을수록 좋다.
Conclusion
본 논문에서는 SISR를 위한 모델인 DRRN을 소개했다.
DRRN은 더 발전된 residual unit을 사용한 residual block으로 이루어져있다.
DRRN의 구조가 reasonable하고 그 성능이 뛰어난 것은 실험적으로 확인했다.
Reference
Tai, Ying, Jian Yang, and Xiaoming Liu. "Image super-resolution via deep recursive residual network." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.



